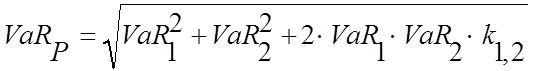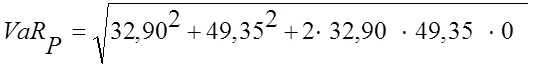Bei Banken und auch Versicherungen hat
die Risiko-Kennzahl "Value
at Risk" seit Mitte der 90er Jahre einen fast kultartigen
Status erreicht. In den letzten Jahren wird sie auch vermehrt
in anderen Branchen und Risikobereichen angewendet. Übersetzt
man "Value at Risk" wörtlich, so erhält man
den "gefährdeten Wert" oder das "Vermögen das
einem Risikoausgesetzt ist". Doch was steckt
genau hinter dieser Kennzahl? Inwieweit
ist sie geeignet, ein Risiko korrekt zu
bewerten?
Der VaR zum Konfidenzniveau 1-α
ist das α-Quantil der Verteilung der
Wertveränderung (Gewinne und Verluste) einer Risikoposition
über die Haltedauer. Der VaR ist
ein Downside-Risikomaß, das nur der Messung
potenzieller Verluste dient ("downside risk"), das heißt nur
das "negative Ende" der Wahrscheinlichkeitsverteilung fließt in
die Analyse ein.
Warum Value at Risk?
Bei Banken und auch Versicherungen hat
die Risiko-Kennzahl "Value
at Risk" seit Mitte der 90er Jahre einen fast
kultartigen Status erreicht. In den letzten Jahren wird sie
auch vermehrt in anderen Branchen und Risikobereichen
angewendet. Übersetzt man "Value at Risk"
wörtlich, so erhält man den "gefährdeten Wert" oder das
"Vermögen das einem Risikoausgesetzt ist".
Doch was steckt genau hinter dieser Kennzahl?
Inwieweit ist sie geeignet,
ein Risiko korrekt zu bewerten?
Die statistischen Bewertungskonzepte des Risikomanagements
sind vielfältig: Sie reichen von einfachen Checklisten über
die Extremwert-Theorie bis zu neuronalen Netzen.
Insbesondere die Finanzdienstleister haben in den
vergangenen Jahrzehnten ausgefeilte statistische und
mathematische Methoden zur
risikoadäquaten Berechnung der Prämien entwickelt.
Viele "Finanzingenieure" unterliegen jedoch dem
Trugschluss, man könne die komplexe (Wirtschafts-)Welt mit
einer Maschine vergleichen, die nach klaren
Ursache-Wirkungsketten funktioniert und daher mit
bestimmten interdependenten Verhaltensgleichungen auch
modelliert werden kann. Trotz aller Fehlprognosen überwiegt
der Charme einer Risikoaussage mit einem konkreten
Zeithorizont, Risikobetrag und
einer Wahrscheinlichkeit. Vor diesem
Hintergrund hat sich in den vergangenen Jahren
der Value at Risk als "Standard-Risikomaß"
herausgebildet.
Die Geburtsstunde des Value at Risk
Dennis Weatherstone verlangte während seiner Zeit als
Vorsitzender der US-amerikanischen Investmentbank J.P. Morgan täglich
um 16.15 Uhr einen
einseitigen Risiko-Bericht, in dem das
gesamte Marktexposure des Handelsbestandes der Bank sowie
eine Schätzung der möglichen Verluste in den folgenden 24
Stunden dargestellt waren. Weatherstone war es einfach leid,
dass die Marktrisiken der verschiedenen Finanzinstrumente mit
unterschiedlichen Methoden gemessen
wurden. Sein bisheriger Report enthielt eine Unmenge von
Beta-Faktoren und Volatilitäten, gearing factors, Deltas,
Gammas und Thetas. Er wollte ein
einheitliches Risiko-Maß für alle
Finanzinstrumente haben.
Dies war die Geburtsstunde des "Report 4.15". Im Oktober 1994
veröffentlicht J.P. Morgan sein
Produkt
RiskMetrics™ und stellten es allen Interessenten
unentgeltlich zur Verfügung (www.jpmorgan.com/). Im Kern basiert dieses
Produkt auf einer
Methodik, die als "Value at Risk" bezeichnet
wurde.
Definition und Berechnung des Value at Risk
Definiert wird der Value at Risk als der
absolute Wertverlust einer im Unternehmen
definierten Risiko-Position, der mit einer
zuvor
definierten Wahrscheinlichkeit(Konfidenzniveau)
innerhalb eines fest bestimmten Zeitraums (Halteperiode)
nicht überschritten wird [von Balduin 2003, S. 41 sowie
Romeike/Hager 2009, S. 203 und Romeike/Hager 2013, S.
191].
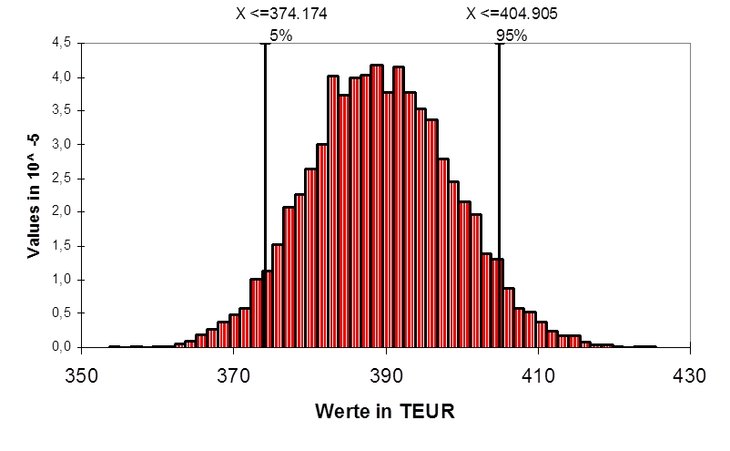
In der folgenden Abbildung wird der Value at
Risk dargestellt. Von den simulierten
Vermögenswerten liegen 90 Prozent in dem Intervall zwischen
374.174 und 404.905 EUR. Je 5 Prozent liegen drüber oder
drunter. In der Regel wird ein noch höherer Vermögenswert
nicht als Risiko ("downside risk")
angesehen, so dass die 5 Prozent extrem guten in
die Wahrscheinlichkeit eingerechnet
werden, mit der eine Verlustmarke nicht unterschritten werden
kann. In dem konkreten Beispiel lautet die Aussage: Mit 95
Prozent Wahrscheinlichkeit wird das
Vermögen nicht unter den 374 TEUR liegen.
Der Value at Risk als Standardrisikomaß
Für die Berechnung des Value at
Risk müssen bestimmte Voraussetzungen erfüllt
sein:
Die Risiken müssen in Einzelkategorien zerlegt und mit
einer geeigneten Verteilungsfunktion beschrieben werden,
die Abhängigkeiten zwischen den Risiken sollten bekannt
sein bzw. geschätzt werden können,
die Eigenschaften der Risiken müssen im Zeitablauf
einigermaßen stabil und prognostizierbar sein
(Extremszenarien werden nicht berücksichtigt),
es muss eine gesicherte Datenbasis vorhanden sein.
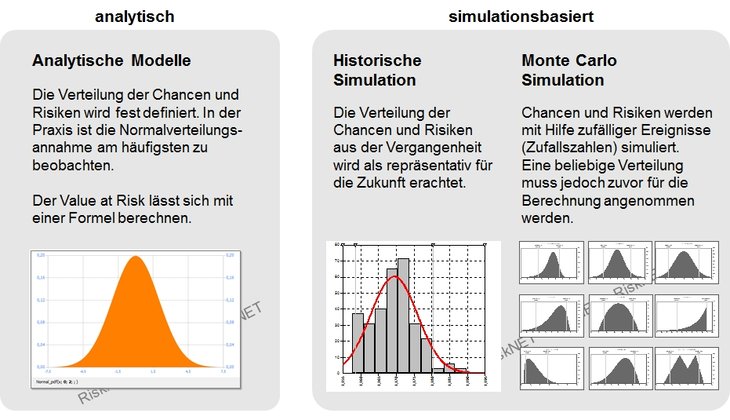
Zur Messung des Value at Risk kann man
grundsätzlich zwischen zwei verschiedenen Ansätzen
unterscheiden: Einem analytischen Ansatz und einem
Simulationsansatz [vgl. Eisele/Knobloch 2000, 160f.].
Analytische Ansätze und Simulationsansätze zur
Berechnung des VaR
Diese beiden Ansätze unterscheiden sich im Wesentlichen in
zwei Punkten, nämlich der Modellierung der
Entwicklung der Risikofaktoren und der Sensibilität der
betrachteten Portfolios bzw. Positionen. Während im Rahmen
des analytischen Ansatzes das Modell auf der
Grundlage von bekannten Zusammenhängen und Beziehungen
zwischen den einzelnen Variablen mit Hilfe einer
Verteilungsannahme gebildet wird, errechnet sich
der Value at Riskbeim Simulationsansatz
anhand der Simulation verschiedener
Zustandsentwicklungen.
Die Historische Simulation bedient
sich dabei vergangenheitsbezogener Daten. Hierbei wird
unterstellt, dass alle Risikofaktoren aus der Vergangenheit
auch in Zukunft den Wert der Risikoposition in gleicher Weise
beeinflussen werden. Die Historische Simulation ist
wegen ihres geringen mathematischen Anspruchs einfach zu
implementieren. Die Anwender müssen
sich nicht mit der Messung von Volatilitäten und
Korrelationen auseinandersetzen. Es werden auch keine
Kenntnisse von Loga¬rithmus, e-Funktion,
Matrizenmultiplikation oder gar der Simulation von
Zufallszahlen benötigt. Der Einfachheit des Ansatzes steht
die Beschränkung auf die Vergangenheit gegenüber, was von
Kritikern häufig mit dem Lenken eines Autos durch den Blick
in den Rückspiegel verglichen wird. Ist der gewählte
historische Zeitraum nicht repräsentativ für die Zukunft,
schlägt das Modell fehl.
Ebenso können keine Ereignisse simuliert werden, die zwar
möglich aber noch nie beobachtet worden sind.
Die stochastische Simulation (siehe
Monte-Carlo-Methode bzw. Monte-Carlo-Simulation)
basiert nicht auf historischen Werten, sondern auf einer
stochastischen Variation der unterschiedlichen
Modellparameter. Im Rahmen dieses stochastischen Ansatzes
werden neben den
einzelnen Risiko-Positionen und ihren
Einflussfaktoren auch die Korrelationen zu
anderen Risiko-Positionen berücksichtigt.
Die stochastische Simulation gilt
wegen ihrer Flexibilität gegenüber anderen Verfahren als
überlegen, insbesondere bei der Risikomessung von komplexen
Exposures wie sie beispielsweise aus Derivaten resultieren.
Die Monte Carlo Simulation kann
beliebige Verteilungen, Restlaufzeitverkürzungseffekte,
Volatilitätsclustering, fat tails, nichtlineare Exposures und
Extremszenarios in der Risikoberechnung berücksichtigen. Als
Nachteile sind der hohe Rechenaufwand und
die Komplexität der eingesetzten
statistischen Verfahren zu nennen.
Dem gegenüber hat das analytische Verfahren eine je nach
Anwendungsfall ähnliche Komplexität, erzeugt
jedoch deutlich weniger Rechenaufwand. Der
sogenannte Varianz-Kovarianz-Ansatz weist
aber den häufig kritisierten Nachteil auf, dass für alle
Risikofaktoren
eine Normalverteilung unterstellt wird.
Für die Praxis kann das Varianz-Kovarianz-Modell als
erste schnelle Lösung dienen, um beispielsweise einen groben
Eindruck von den aktuell bestehenden Risiken zu erhalten.
Grenzen des Value at Risk
Wie jede Modellbildung stellt auch die Berechnung
des Value at Risk eine Gradwanderung
zwischen Komplexität und Genauigkeit
dar. So bauen etwa die analytischen Bewertungskonzepte auf
normalverteilten Einzelrisiken auf, da die entstehenden
Modelle ansonsten zu komplex und dadurch nicht mehr
handhabbar wären. Ähnliche Kompromisse müssen auch bei den
Verfahren der Historischen und der Monte Carlo
Simulationeingegangen
werden. Hier wird zwar in der Regel auf die Annahme
der Normalverteilungverzichtet, allerdings
kann naturgemäß nur eine endliche Auswahl der unendlichen
Anzahl möglicher Entwicklungen und Umweltgegebenheiten
berücksichtigt werden. Einerseits stellen diese
Vereinfachungen und Einschränkungen eine notwendige
Voraussetzung dar, um die Berechnung überhaupt durchführen zu
können. Andererseits führen sie aber auch zu Ungenauigkeiten,
da das Modell immer
unvollständig bleiben muss.
Neben diesen methodischen Defiziten, die zwangsläufig in Kauf
zu nehmen sind, wird auch die ökonomische Interpretation der
Kennzahl Value
at Risk häufig kritisiert. Als Ergebnis der
Berechnungen wird ein Wert angegeben, der mit einer
festgelegten Wahrscheinlichkeit von
beispielsweise 95 Prozent nicht überschritten wird. Bei einer
solchen Definition werden jedoch
die Risiko-Werte mit
einer Wahrscheinlichkeit von größer 95
bis 100 Prozent nicht berücksichtigt. Würde man
das Konfidenzniveau auf 99,5 Prozent
erhöhen, könnte eine größere Anzahl an Szenarien abgebildet
werden, eine unbekannte Restgröße mit einer sehr geringen
Eintrittswahrscheinlichkeit würde jedoch auch hier erhalten
bleiben (0,5 Prozent). Allgemein formuliert kann das
β-Perzentil auch als 200-Jahresereignis interpretiert werden.
Bei einem 200-Jahresereignis geht es um ein Schadenereignis,
welches im Mittel alle 200 Jahre auftreten wird.
Dabei wird keinerlei Aussage über die Periodizität getroffen,
das heißt das Schadensereignis muss nicht in Zeitintervallen
von 200 Jahren auftreten. Es kann auch beispielsweise fünf
Mal hintereinander eintreten, danach lange Zeit nicht mehr
und die Modellannahme war trotzdem richtig. Ebenso ist die
Wahrscheinlichkeitsaussage mit einer eigenen
Irrtumswahrscheinlichkeit belegt, so dass in einem
Modellbacktesting von
der Wahrscheinlichkeit in berechneten
Bandbreiten nach unten und oben abweichende Beobachtungen
zulässig sind ohne dass das Modell abgelehnt
werden könnte.
Risikomaß für Sonnenwetter und Schlechtwetter
Etwas überspitzt kann gesagt werden, dass der Value
at Risk damit genau den Bereich der
Wahrscheinlichkeitsverteilung nicht betrachtet, die für das
Überleben eines Unternehmens (und damit für
das Risikomanagement)
besonders relevant ist. Damit kann der Value at
Risk auch als Schönwetter-Risikomaß interpretiert
werden.
Während für Weatherstone der
Ein-Prozent-Wahrscheinlichkeitsbereich akzeptabel war, sollte
man vorsichtig sein, dies auch auf
Kreditrisiken, Derivate oder
operationelle Risiken zu übertragen. Gerade die Ereignisse
des 11. September 2001, die Flutkatastrophe vom August 2002
in Mittel- und Osteuropa oder das Tōhoku-Erdbeben im Jahr
2011haben gezeigt, dass gerade diese "low frequency, high
severity"-Ereignisse (Extremereignisse) fatale Auswirkungen
haben können.
Ergänzende Methoden wie
die Szenarioanalyse oder die
Extremwerttheorie (Extreme Value Theory) können helfen, diese
Informationslücke bei
der Risikoquantifizierung zu minimieren.
Außerdem bietet der Werkzeugkasten des Risikomanagements
alternative Risikomaße, wie beispielsweise
den Expected Shortfall (ES). Der ES wird
auch als "conditional value at risk"
(CVaR), "average value at risk"
(AVaR) oder "expected tail loss" (ETL)
bezeichnet. Des ES zählt wie der VaR zu
den Downside-Risikomaßen und ist definiert als der erwartete
Verlust für den Fall, dass
der VaR tatsächlich überschritten wird.
Somit ist er der wahrscheinlichkeitsgewichtete Durchschnitt
aller Verluste, die den VaR-Wertübertreffen.
Es werden daher nur die Verluste betrachtet, die über
den VaR hinausgehen.
Unter den Lower Partial
Moments (LPM)
werden Risikomaße verstanden, die sich
als Downside-Risikomaß nur auf einen
Teil der
gesamten Wahrscheinlichkeitsdichte beziehen.
Sie erfassen nur die negativen Abweichungen von einer
Schranke bzw. Zielgröße, werten hier aber die gesamten
Informationen der Wahrscheinlichkeitsverteilung aus (bis zum
theoretisch möglichen Maximalschaden.
Das Phänomen Risiko weist zahlreiche
Facetten auf, denen man nur mit einem Portfolio an Methoden zur
Identifikation und Quantifizierung gerecht werden
kann. Risikomanagementkann
nie die Suche nach einem einzigen, "optimalen" methodischen
Ansatz sein. Ein Risiko-Messsystem, dass uns
"blind" gegenüber anderen, vom Modell nicht
erfassten Risiken macht, suggeriert uns eine
falsche Sicherheit vor und ist daher
auch
als Risiko-Überwachungssystem fragwürdig.
Weiterführende Literaturhinweise:
Balduin, A. von (2003): Operational Value at Risk – Ein
Ansatz für das Management von Operationellen Risiken,
RiskNews 01/2003.
Bankhofer, U. et al (1999): Mathematische Methoden in
der Versicherungswirtschaft – eine empirische Studie,
Arbeitspapiere zur Mathematischen Wirtschaftsordnung,
Augsburg 1999.
Eisele, W./Knobloch, A. P. (2000):
Value at Risk: Tool for Managing Trading Risk, in:
Frenkel, M.; Hommel, U.; Rudolf, M.: Riskmanagement –
Challenge and Opportunity, Heidelberg 2000, S. 155-179.
Hager, P. (2004):
Corporate Risk
Management – Value at Risk und Cash Flow at Risk,
Frankfurt/Main 2004.
Leippold, M. (1998): Value at Risk – Standard mit
Schönheitsfehler, Schweizer Bank 08/1998.
Romeike, F. (2009): Was ist der "Value at Risk"? Oder
besser: Was ist er nicht?, in: Risk, Compliance & Audit
(RC&A), 03/2009, S. 10-11.
Romeike, F./Hager, P. (2009):
Erfolgsfaktor Risk
Management 2.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 2. Auflage, Wiesbaden 2009.
Romeike, F./Hager, P. (2013):
Erfolgsfaktor Risk
Management 3.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 3. Auflage, Wiesbaden 2013.
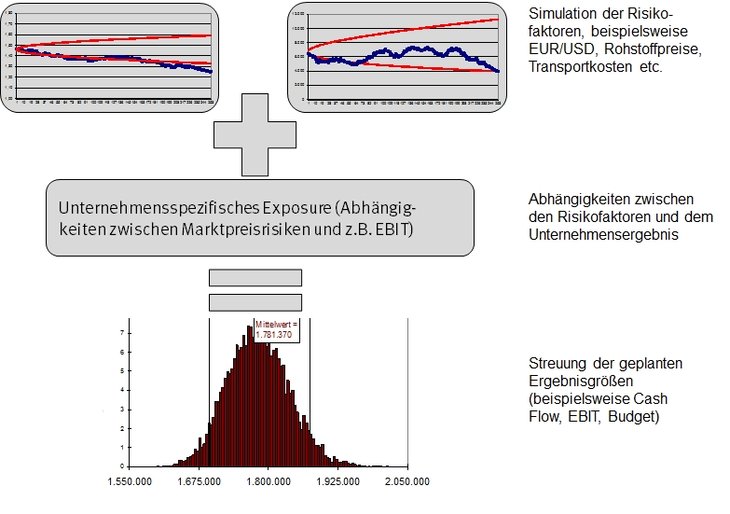
Industrie- und Handelsunternehmen sind einer Vielzahl
potenzieller operativer und strategischer Risiken sowie
Finanzrisiken ausgesetzt. Häufig sind beispielsweise operative
Cash Flows von Markt- und Rohstoffpreisrisiken abhängig. Eine
ungünstige Wechselkursentwicklung kann beispielsweise zu
Exportrückgängen führen. Steigende Rohstoffpreise mindern bei
konstanten Absatzpreisen den Gewinn. Oder eine ungünstige
Zinsentwicklung erschwert den Kapitaldienst und kann geplante
Investitionen unrentabel werden lassen. Alle Risikofaktoren
zusammen können die Liquidität eines Unternehmens gefährden.
Wie wirken sich eine Veränderung der Rohstoffpreise und der
Wechselkurse auf die operativen Cash Flows, den Gewinn oder den
Umsatz aus? Mit welcher Wahrscheinlichkeitwerden
die operativen Cash Flows den Finanzbedarf des Unternehmen decken
(Liquiditätssicherung)? Mit Hilfe
der Cash-Flow-at-Risk-Methode können diese
und weitere Fragen beantwortet werden.
International tätige Unternehmen sind zahlreichen finanziellen
Risiken ausgesetzt. Neben Wechselkursrisiken,
Rohstoffpreisrisiken, Zinsrisiken und Aktienrisiken gibt es
zahlreiche liquiditätswirksame Risiken aus dem operativen
Geschäft. Sowohl Investoren als auch Kunden, Lieferanten und
der Gesetzgeber drängen auf eine transparente
Berichterstattung, um eine objektive Darstellung der Geschäfts-
und Finanzrisiken zu erhalten. Im Mittelpunkt steht die Frage,
wie sich finanzielle Risiken auf die Ertragslage eines
Unternehmens auswirken.
Industrie- und Handelsunternehmen sind im Gegensatz zu reinen
Finanzdienstleistern mit zusätzlichen Unwägbarkeiten
konfrontiert. Häufig sind operative Cash Flows von Markt- und
Rohstoffpreisrisiken abhängig. Eine ungünstige
Wechselkursentwicklung kann beispielsweise zu Exportrückgängen
führen. Steigende Rohstoffpreise mindern bei konstanten
Absatzpreisen den Gewinn.
Eine ungünstige Zinsentwicklung erschwert den Kapitaldienst und
kann geplante Investitionen unrentabel werden lassen. Alle
Risikofaktoren zusammen können die Liquidität eines
Unternehmens gefährden.
Aber wie wirkt sich eine Veränderung der Rohstoffpreise und der
Wechselkurse auf die operativen Cash Flows, den Gewinn oder den
Umsatz aus? Mit
welcher Wahrscheinlichkeitwerden die operativen
Cash Flows den Finanzbedarf des Unternehmens decken
(Liquiditätssicherung)? Wie kann die Planung des Unternehmens
durch Risikoinformationen ergänzt werden, beispielsweise in
Form einer Bandbreitenplanung?
Zur Beantwortung derartiger Fragen bedarf es einer speziell auf
Unternehmen und deren individuelle Risikoposition
zugeschnittenen Methode.
Der Cash-Flow-at-Risk-Ansatz beantwortet
die Frage, wie groß die Abweichung des tatsächlichen Cash Flows
von einem geplanten oder budgetierten Wert mit
einer Wahrscheinlichkeit von
beispielsweise 95 Prozent in den nächsten 12 Monaten aufgrund
von Schwankungen der zugrunde gelegten Risikofaktoren
ist.
Mit dem Earnings-at-Risk-Ansatz erfolgt auf handelsrechtlicher
Ebene eine ähnliche Betrachtung. Hier stehen nicht die
pagatorischen Ein- und Auszahlungen (Cash Flows) im
Vordergrund, sondern handelsrechtliche Gewinne und Verluste. So
lässt sich beispielsweise ermitteln, wie groß die Abweichung
des handelsrechtlichen Gewinns von einem geplanten Jahresgewinn
mit 95
Prozent Wahrscheinlichkeit ausfallen
kann.
Der Ansatz des Value at Risk dient der
Messung von Risiken aus Vermögenspositionen wie beispielsweise
Aktienportfolios, Rentenportfolios oder Rohstoffvorräten.
Demgegenüber dient
die Cash-Flow-at-Risk-Methodik einer Szenarioanalyse zukünftiger
Cash Flows.
In der folgenden Abbildung ist
die Cash-Flow-at-Risk-Messung schematisch
dargestellt. Mit Hilfe stochastischer Szenariomethoden werden
für alle relevanten Risikofaktoren Vertrauensintervalle für
einen Zeitraum von 12 Monaten geschätzt.
Die statistischen Prognoseverfahren simulieren eine Vielzahl
von Szenarien für die Entwicklung der relevanten
Risikofaktoren. Zu jedem Risikofaktor wird ein
zweiseitiges Vertrauensintervall erstellt.
Für jedes Szenario (=
Veränderung eines Risikofaktors) wird die Auswirkung auf die
operativen Cash Flows analysiert. So entsteht eine
Häufigkeitsverteilung der zukünftigen Cash Flows.
Mit Hilfe derartiger Verteilungen kann ein Unternehmen
beispielsweise beurteilen, mit
welcher Wahrscheinlichkeit ein
erwarteter Cash Flow tatsächlich
realisierbar ist, wie groß die Abweichung von diesem Zielwert
mit einer
bestimmten Wahrscheinlichkeit ausfällt,
oder mit welcher Wahrscheinlichkeit die
Liquidität des Unternehmens gefährdet sein kann.
Das Cash-Flow-at-Risk-Verfahren wurde in
den letzten Jahren von rein finanziellen Risiken auf das
gesamte operative Geschäft von Unternehmen ausgedehnt.
Inzwischen wird es selbst von kleineren Mittelständlern zur
Planung und Risikoanalyse der
zukünftigen Liquiditätsentwicklung verwendet, um so frühzeitig
mögliche Engpässe zu erkennen und Gegenmaßnahmen zur
Liquiditätssicherung zu ergreifen.
Weiterführende Literaturhinweise:
Hager, P. (2004):
Corporate Risk Management
– Value at Risk und Cash Flow at Risk, Frankfurt/Main 2004.
Romeike, F./Hager, P. (2009):
Erfolgsfaktor Risk Management
2.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 2. Auflage, Wiesbaden 2009.
Romeike, F./Hager, P. (2013):
Erfolgsfaktor Risk Management
3.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 3. Auflage, Wiesbaden 2013.
Die Quantifizierung von Risiken kann grundsätzlich auf zwei
Wegen erfolgen, analytisch oder durch Simulation.
Für den analytischen Weg bedarf es einer Verteilungsannahme.
Beim Varianz-Kovarianz-Modell wird
die Stochastik der Risikofaktoren
(Volatilitäten und Korrelationen) durch eine Kovarianzmatrix
beschrieben, wobei von multivariat normalverteilten Änderungen
der Risikofaktoren ausgegangen wird. Der Vorteil
des Varianz-Kovarianz-Modells liegt darin,
dass eine einfache und schnelle Analyse von
Diversifikations- und Hedgeeffekten zwischen den
Portfoliobestandteilen ermöglicht wird.
Das Varianz-Kovarianz-Modell existiert
in zwei Varianten, dem Delta-Normal-Ansatz und dem
Delta-Gamma-Ansatz.
Die Quantifizierung von Risiken kann grundsätzlich auf zwei
Wegen erfolgen, analytisch oder durch Simulation.
Für den analytischen Weg bedarf es einer
Verteilungsannahme.
Dem Varianz-Kovarianz-Modell (bzw. Varianz-Kovarianz-Ansatz
bzw- Delta-Normal-Ansatz) liegt
eine Normalverteilung zu Grunde. Das
Modell dient
zur Messung des Value at Risk einer
Vermögensposition. Der Value at
Risk ist der mögliche Verlust, der mit einer
vorgegebenen Wahrscheinlichkeit innerhalb
einer festgelegten Periode nicht überschritten wird.
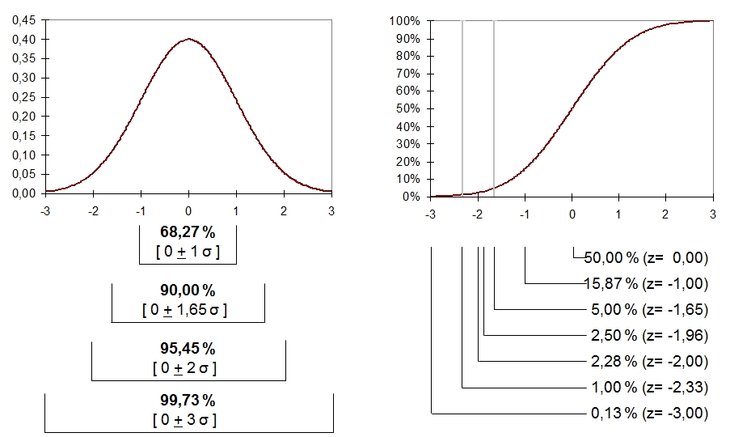
Dichtefunktion und Verteilungsfunktion der
Normalverteilung
Die Normalverteilung (Gauß-Verteilung)
ist eine symmetrische Glockenkurve und
bildet den Kern des Varianz-Kovarianz-Modells
(vgl. Abbildung oben). Mit den beiden
Parametern Erwartungswert und Standardabweichung wird
die Verteilung vollständig beschrieben. Für die Risikomessung
wird die Standardabweichung mit einem
Faktor für die
gewünschte Wahrscheinlichkeit der
Aussage multipliziert. Die Gültigkeit der
Normalverteilungsannahme vorausgesetzt, führt der z-Wert
1,6449 zu einer Aussagewahrscheinlichkeit von 95 Prozent und
der z-Wert von 2,3263 zu 99 Prozent. Dabei ist zu beachten,
dass die z-Werte ein
zweiseitiges Vertrauensintervall beschreiben.
Der z-Wert von 1,6449 umschließt ein
zweiseitiges Vertrauensintervall um
den Mittelwert das 90 Prozent der
Wahrscheinlichkeitsmasse beinhaltet. Vereinfacht ausgedrückt
liegen links davon 5 Prozent mit Risiken und rechts davon 5
Prozent mit Chancen. Für die Risikoaussage werden die 5
Prozent mit Chancen den 90 Prozent in der Mitte zugeschlagen
und ergeben die gewünschten 95 Prozent
Aussagewahrscheinlichkeit.
Der Value at Risk einer einzelnen
Vermögensposition ergibt sich aus der Multiplikation von
ihrem Marktwert mit
seiner Volatilität in Prozent und dem
Z-Wert. Bei einer Aktie A mit dem Kurs 100 und
einer Volatilität von 20 Prozent p.
a. ergibt sich
der Value at Risk mit
95-prozentiger Wahrscheinlichkeit auf
einen Planungshorizont von einem Jahr wie folgt: 100 * 0,20 *
1,6449 = 32,90. Mit 95
Prozent Wahrscheinlichkeit wird unter
normalen Umweltbedingungen binnen eines Jahres der
Kursverlust nicht größer als 32,90 sein.
Setzt sich ein Portfolio aus mehreren unterschiedlichen
Vermögenspositionen zusammen, bedarf es
einer Aggregation der einzelnen
Value-at-Risk-Beträge zu einem Portfolio-Value-at-Risk. Bei
einer einfachen Addition der Risikobeträge würden die häufig
vorhandenen Diversifikationseffekte unbeachtet bleiben. Eine
Aussage über die mögliche Diversifikationswirkung zwischen
zwei Vermögenspositionen liefert
deren Korrelationskoeffizient. Die
risikodiversifizierende Wirkung des Korrelationskoeffizienten
wird für ein Beispiel-Portfolio berechnet. Zu der oben
beschriebenen Aktie A wird eine zweite Aktie mit dem gleichen
Kurswert 100 jedoch
einer Volatilität von 30 Prozent p.
a. hinzugefügt.
Deren Value at Risk beträgt mit
95-prozentiger Wahrscheinlichkeit für
einen Planungshorizont von einem Jahr folgerichtig: 100 *
0,30 * 1,6449 = 49,35.
In einem zweiten Schritt stellt sich die Frage nach der
korrekten Aggregation beider VaR-Kennzahlen.
Die einfache Addition der beiden Value-at-Risk-Werte führt zu
einem Gesamtrisiko von 82,25 bei einem Gesamtvermögen von
200. Bei der Addition zwischen den beiden Risikofaktoren wird
implizit eine Korrelation von 1
angenommen. Jedoch sind in der Praxis häufig geringere
Korrelationen zwischen Risikofaktoren beobachtbar. Mit
einer Korrelation unter 1 können
Risikodiversifikationseffekte realisiert werden, die in der
bisherigen Berechnung noch nicht betrachtet wurden.
Die Korrelation zwischen den beiden
Risikofaktoren kann mit Hilfe der nachfolgenden Gleichung
berücksichtigt werden, welche an eine Formel aus dem
Portfolio-Selection-Modell von
Markowitz zur Berechnung des Portfoliorisikos im
Zwei-Anlagen-Fall angelehnt ist.
Berücksichtigung von Korrelation zwischen zwei
Risikofaktoren basierend auf dem
Portfolio-Selection-Modell
von Markowitz
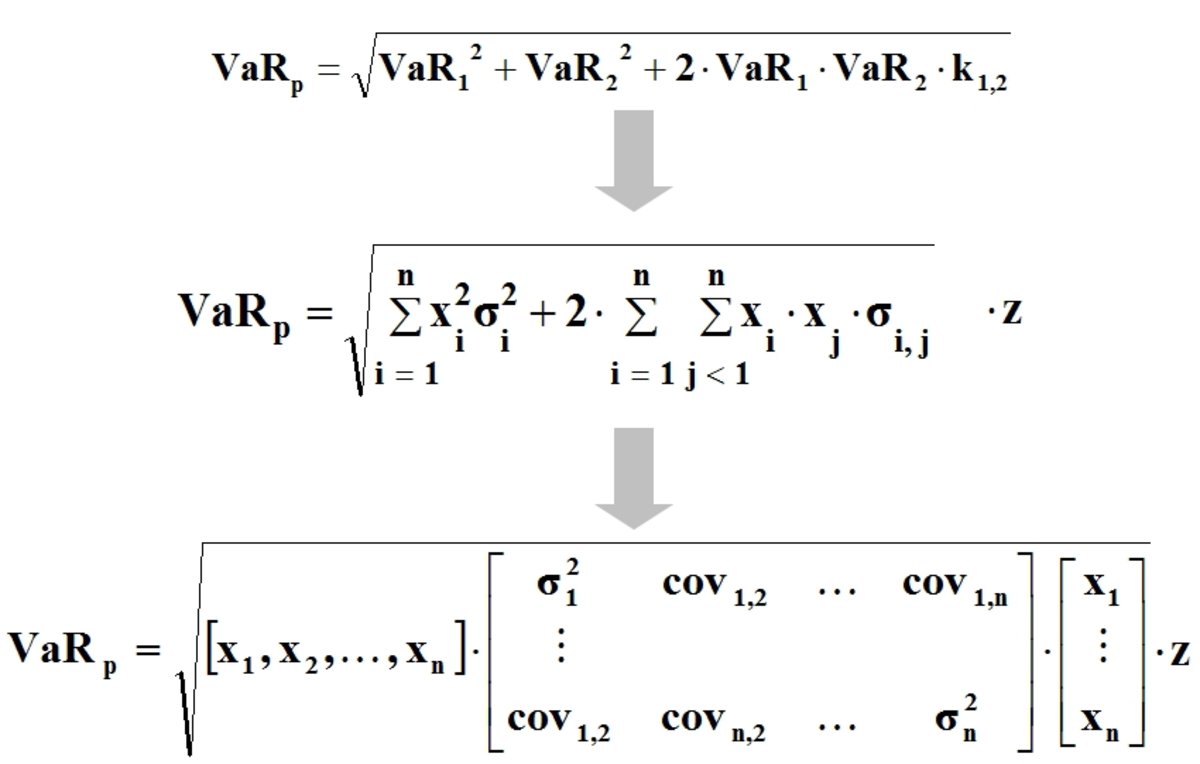
Im Folgenden wird das Gesamtrisiko für den obigen
Zwei-Aktien-Fall unter der Annahme
einer Korrelation zwischen A und B von
Null gerechnet. Der Value at Risk des
Portfolios ergibt sich aus
Das Varianz-Kovarianz-Modell
für den Zwei-Asset-Fall und für beliebig viele
Assets
und beträgt 59,31 mit
95-prozentiger Wahrscheinlichkeit auf
einen Planungshorizont von einem Jahr. Gegenüber dem
undiversifizierten Value at Risk der zu
82,25 addierten Einzelrisiken entspricht dieser Wert einer
Reduktion von knapp 30 Prozent. Für den Fall von mehr als
zwei Wertpapieren wird statt der oben gezeigten Formel mit
einer Wurzel dann eine Matrizenmultiplikation verwendet (vgl.
Abbildung unten). In den Matrizen stehen die Varianzen und
statt der Korrelationen die Kovarianzen der Risikofaktoren
woraus der Name des für beliebig viele Risikofaktoren
gültigen Modells
resultiert: Varianz-Kovarianz-Modell[vgl.
Romeike/Hager 2013, S. 313 ff].
Delta-Gamma-Ansatz
Das Varianz-Kovarianz-Modell existiert
in zwei Varianten, dem Delta-Normal-Ansatz und dem
Delta-Gamma-Ansatz. Der Delta-Normal-Ansatz unterstellt, dass
die Marktwerte der Positionen im Portfolio linear auf
Veränderungen der Risikofaktoren reagieren und ist daher für
die Risikoberechnung von Portfolios mit symmetrischen
Gewinn-/Verlustprofilen geeignet. Die zweite Methode
des Varianz-Kovarianz-Modells bildet der
Delta-Gamma-Ansatz. Darin wird die Veränderung des Δ durch
eine weitere Kennzahl
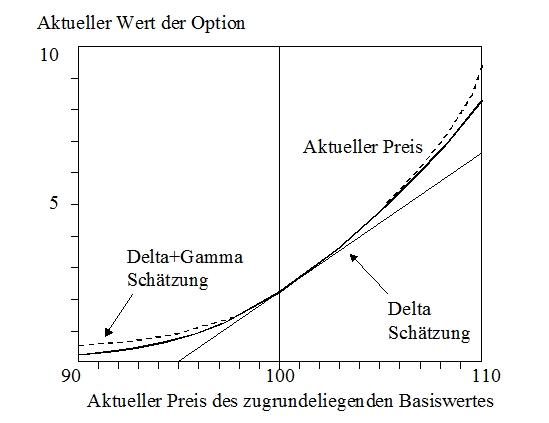
berücksichtigt. Das Г (Gamma) gibt die Veränderungsrate des Δ
bezüglich der Veränderung des Kassakurses an. Nachfolgende
Abbildung zeigt den konvexen Zusammenhang zwischen der
Wertänderung eines Basisinstruments (beispielsweise einer
Aktie) und einer darauf bezogenen Option. Das
Gewinn-/Verlustprofil von Optionen ist
asymmetrisch, gegen Zahlung einer Prämie werden nur die
Chancen realisiert und Risiken vermieden. Im Gegensatz zu der
Annahme einer linearen Beziehung im Delta-Normal-Ansatz kann
die Delta-Gamma-Variante die Konvexität der Wertebeziehung
näherungsweise abbilden. So lässt sich approximativ die
Wertänderung der Option bei einer kleinen Wertänderung des
Basiswertes schätzen. Trotzdem liefert auch der
Delta-Gamma-Ansatz nicht die exakten Ergebnisse wie sie bei
einer Neubewertung der Position zu erzielen sind.
Das Varianz-Kovarianz-Modell
für den Zwei-Asset-Fall und für beliebig viele
Assets
Fazit
Die zuerst
genannte Delta-Normal-Methode hat
gegenüber allen anderen Methoden zur
Risikomessung einen Vorteil: Die besonders schnelle und
einfache Risikoschätzung. Davon abgesehen benötigt das
Modell eine Reihe
von Annahmen, die in der Realität nicht vollständig erfüllt
sind. Am häufigsten wird die Annahme normalverteilter
Veränderungen der Risikofaktoren kritisiert.
Die Delta-Normal-Methode führt zu
falschen Risikoprognosen, wenn in dem betrachteten
Portfolio Optionen enthalten sind. Das
Ausmaß des Fehlers wächst mit dem Portfolioanteil
asymmetrischer Produkte. Als
Alternative wird die Delta-Gamma-Methode zur Lösung des
Problems vorgeschlagen. Die Anwendung der Delta-Gamma-Methode
liefert für Portfolios mit optionalen Produkten exaktere
Value-at-Risk-Schätzungen als
die Delta-Normal-Methode. Dennoch kommt es
auch bei der Delta-Gamma-Methode zu fehlerhaften
Risikoeinschätzungen, wenn die Restlaufzeit
der Optionen gegen Null strebt und/oder
die Optionen im Geld sind.
Für die Praxis kann das Varianz-Kovarianz-Modell als
erste schnelle Lösung dienen, um beispielsweise einen ersten
Eindruck von den aktuell bestehenden Risiken zu erhalten. So
könnte die tägliche Risikoüberwachung mit
einem Varianz-Kovarianz-Modell erfolgen
und in gewissen Abständen wären die Risikoschätzungen mit
Hilfe von exakteren, aber komplexen und rechenaufwendigen
Modellen zu prüfen.
Die Fehlermöglichkeits- und Einflussanalyse
bzw. Ausfalleffektanalyse (FMEA = Failure Mode and Effects
Analysis) ist eine systematische, halbquantitative
Risikoanalysemethode. Sie wurde ursprünglich zur Analyse von
Schwachstellen (Risiken) technischer und militärischer Systeme
oder Prozesse entwickelt.
So wurde die FMEA beispielsweise
in den sechziger Jahren für die Untersuchung
der Sicherheit von Flugzeugen entwickelt und
anschließend auch in der Raumfahrt, für Produktionsprozesse in
der chemischen Industrie und in der Automobilentwicklung
verwendet.
FMEA folgt
dem Grundgedanken einer vorsorgenden Fehlervermeidung anstelle
einer nachsorgenden Fehlererkennung und -korrektur
(Fehlerbewältigung) durch frühzeitige Identifikation und
Bewertung potenzieller Fehlerursachen bereits in der
Entwurfsphase.
Die Fehlermöglichkeits- und Einflussanalyse
bzw. Ausfalleffektanalyse (FMEA = Failure Mode and
Effects Analysis) ist eine systematische,
halbquantitative Risikoanalysemethode.
Sie wurde ursprünglich zur Analyse von
Schwachstellen (Risiken) technischer und militärischer Systeme
oder Prozesse
entwickelt. So wurde die FMEA beispielsweise
in den sechziger Jahren für die Untersuchung
der Sicherheit von Flugzeugen entwickelt
und anschließend auch in der Raumfahrt, für Produktionsprozesse
in der chemischen Industrie und in der Automobilentwicklung
verwendet.
Die FMEA wurde
unter anderem auch nach dem Störfall im Druckwasserreaktor
"Three Miles Island" in Harrisburgh/Pennsylvania vom 28. März
1979 auch für Nuklearanlagen empfohlen.
Heute empfehlen viele Standards, beispielsweise im Qualitätsmanagement,
den Einsatz der FMEA. Die
Kernidee der FMEA basiert
auf dem frühzeitigen Erkennen und Verhindern von potenziellen
Fehlern sowie deren Auswirkungen auf die Produktfunktionen.
Die FMEAanalysiert
daher präventiv Fehler und deren Ursache. Sie bewertet Risiken
bezüglich Auftreten, Bedeutung und ihrer Entdeckung.
Hierbei gilt die einfache Logik: Je früher ein Fehler erkannt
wird, desto besser. Eine Fehlerfortpflanzung von der Forschung
und Entwicklung bis zum Produkt bedeutet
fast immer eine Potenzierung des Aufwandes.In der Praxis werden
unterschiedliche Arten von FMEA unterschieden:
System-FMEA: Hierbei
liegt der Fokus vor allem auf einem einwandfreien
Funktionieren der einzelnen Systemkomponenten. Bereits in
einer sehr frühen Produktplanungsphase werden Überlegungen
zum Gesamtrisiko, wie etwa unsichere Marktanteile,
Kostenbeherrschung, Make or Buy, Sicherheit,
Werbe- und Vertriebsstrategien oder Fragen der
Umweltverträglichkeit gestellt.
Konstruktions-FMEA: Der
primäre Fokus liegt hierbei vor allem bei einem einwandfreien
Funktionieren der einzelnen Produktkomponenten. Hierbei wird
der konkrete Produktentwurf, bevor er in der
Detailkonstruktion weiterbearbeitet wird, von Fachleuten der
Konstruktion, der Produktion, des Verkaufs, des
Kundendienstes und der Qualitätsabteilung auf
Produktionsrisiken, Prüfrisiken oder Materialrisiken
untersucht.
Prozess-FMEA: Hierbei
liegt der Fokus vor allem beim Aufbau von einwandfreien
Prozessen zur Herstellung der Bauteile und Systeme. Bevor die
Einzelteile und Baugruppen in die Produktion gehen,
untersucht ein Team von
Experten die Realisierungsrisiken und legt fest, welche
möglichen prozessbegleitenden Maßnahmen zur besseren
Beherrschung notwendig werden.
Hardware-FMEA: Hierbei
wird das Ziel verfolgt,
Risiken aus dem Bereich Hardwareentwicklung und -produktion
sowie Elektronik zu analysieren, zu bewerten und mit
Maßnahmen präventiv zu steuern.
Software-FMEA: Hierbei
wird das Ziel verfolgt,
Risiken im Bereich der Softwareentwicklung präventiv zu
erkennen und zu bewerten sowie mit Maßnahmen präventiv zu
steuern.
In einem ersten Schritt wird das Unternehmen
als intaktes und störungsfreies System beschrieben
und abgegrenzt. In einem zweiten Schritt wird
das Gesamtsystem in unterschiedliche Funktionsbereiche oder
ähnliches zerlegt. In einem dritten
Schritt werden sodann die potenziellen
Störungszustände der einzelnen Komponenten untersucht. Hierbei
werden auch systemdurchgreifende Störungen erfasst. In einer
abschließenden vierten Stufe werden die
Auswirkungen auf das Gesamtsystem abgeleitet.
Ein wesentlicher Vorteil
der Ausfalleffektanalyse ist die klare
Formalisierung mit Hilfe von "Worksheets" (Arbeitsblättern),
die neben der Funktion, die
Fehlerursache, die Fehlerwirkung, die bedrohten Objekte
(targets) sowie
die Risikobewertung hinsichtlich
Eintrittswahrscheinlichkeit und Schadensausmaß
(Probability/Severity) enthalten (Vgl. Abbildung oben).
Ein wesentlicher Mangel der FMEA-Methode besteht
auch darin, dass Interdependenzen, dass heißt Abhängigkeiten
zwischen den einzelnen Komponenten des Gesamtsystems, nicht
analysiert werden. Jedoch wurden in der Zwischenzeit eine
ganze Reihe von Ergänzungen zur
traditionellen FMEA entwickelt.
So ist die System-FMEA ebenso
wie die klassische Prozess-FMEA eine
systematische und halbquantitative Risikoanalysemethode, die
im Unterschied zur FMEA die
möglichen Fehler auf der Ebene des Produktes und der
möglichen Auswirkungen auf den Kunden bewertet. Der Ansatz
der System-FMEA verbindet
Produkt und
Prozess, wodurch
eindeutige Ursache-Wirkungs-Ketten dargestellt werden können.
Heute wird die FMEA vor
allem basierend auf Qualitätsmanagement-Systemen
(ISO 9000 ff) in
vielen Unternehmen angewendet.
Die Bewertung bei der FMEA erfolgt
in der Regel durch eine Experteneinschätzung in
interdisziplinären Teams, die jeweils Punkte von "10" bis "1"
vergeben (rein qualitative Risikobewertung).
Hierbei wird immer von der höheren Bewertung zur niedrigeren
Bewertung abgestuft.
Bedeutung des Risikos (hoch = "10" bis gering =
"1").
Auftretenswahrscheinlichkeit der Ursache (hoch = "10"
bis gering = "1")
Entdeckenswahrscheinlichkeit der Ursache oder des
Fehlers im Prozess, vor
Übergabe an den Kunden (gering = "10" bis hoch = "1")
Die
Kennzahlen B, A und E zur Bedeutung
(der Fehlerfolge, "Severity"), Auftretenswahrscheinlichkeit
(der Fehlerursache, "Occurrence") und
Entdeckungswahrscheinlichkeit (des Fehlers oder seiner Ursache,
"Detection") bilden die Basis
zur Risikobewertung. Die Kennzahlen sind
ganzzahlige Zahlenwerte zwischen 1 und 10.
Mit der Berechnung
der Risiko-Prioritätszahl (RPZ)
wird eine Rangfolge der Risiken abgeschätzt.
Die RPZ entsteht durch Multiplikation der
B-, A- und E-Bewertungszahlen (RPZ= B ⋅ A
⋅ E) und kann Werte zwischen 1 und 1000 annehmen.
Weiterführende Literaturhinweise:
Eberhardt, O. (2012): Risikobeurteilung mit FMEA, Renningen
2012.
Romeike, F./Hager, P. (2013):
Erfolgsfaktor Risk Management
3.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 3. Auflage, Wiesbaden 2013.
Werdich, M. (2013): FMEA –
Einführung und Moderation, 2. Auflage, Wiesbaden 2013.
Mit Beginn der 1960er Jahre wurden Techniken zur systematischen
Analyse
sicherheitskritischer Systeme entwickelt. Dazu gehören neben
der Hazard and Operability Analysis (HAZOP) und
der FMEA auch
die Fehlerbaumanalyse (fault tree
analysis, FTA), die im Jahr 1961 als deduktives
Verfahren in den Bell Telephone Laboratories entwickelt wurde.
Ziel war
ursprünglich die Analyse des
Abschusskontrollsystems für die von Boeing hergestellte
Interkontinentalrakete vom Typ LGM-30 Minuteman. In den 1970er
und 1980er Jahren wurde
die Fehlerbaumanalyse unter anderem bei
der Planung von Atomkraftwerken eingesetzt.
Die Fehlerbaumanalyse ist als Methode der
Systemanalyse in der DIN 25424
beschrieben (Fehlerbaumanalyse, Teil 1: Methode und
Bildzeichen, Teil 2: Handrechenverfahren zur Auswertung eines
Fehlerbaumes).
Die Fehlerbaumanalyse nimmt als
Ausgangspunkt – im Gegensatz zur FMEA –
nicht eine einzelne Systemkomponente, sondern das potenziell
gestörte Gesamtsystem.
Die Fehlerbaumanalyse baut auf der
sogenannten negativen Logik auf. Das heißt, der Fehlerbaum
beschreibt eine Ausfallsfunktion die bei dem Zustand
logisch-1 einen Ausfall ausdrückt, bei logisch-0 liegt ein
funktionsfähiges System vor.
Sie gehört zu den "Top-Down"-Analyseformen
im Risikomanagement.
In einem ersten Schritt wird daher das Gesamtsystem
detailliert und exakt beschrieben. Darauf aufbauend wird
analysiert, welche primären Störungen eine Störung des
Gesamtsystems verursachen oder dazu beitragen können.
Ausgangspunkt ist hierbei zunächst ein einziges unerwünschtes
Ereignis, welches
an der Spitze des Fehlerbaums steht, das sogenannte
Top-Ereignis. Das
Top-Ereignis
resultiert in der Regel aus einer Risikoanalyse bzw. Szenarioanalyse.
Der nächste Schritt gliedert die sekundären Störungsursachen
weiter auf, bis schließlich keine weitere Differenzierung der
Störungen mehr möglich oder sinnvoll ist. Der Fehlerbaum
stellt damit alle Basisergebnisse dar, die zu einem
interessierenden Top-Ereignis führen
können.
In der einfachsten Form besteht er aus folgenden Elementen:
Entscheidungsknoten (E), die Entscheidungen kennzeichnen,
Zufallsknoten, die den Eintritt eines zufälligen Ereignisses
darstellen sowie aus Ergebnisknoten (R), die das Ergebnis von
Entscheidungen oder Ereignissen darstellen.
Zwischen diesen Elementen befinden sich
Verbindungslinien
Komplexe Fehlerereignisse werden mittels logischer
Verknüpfung weiter in einfachere Ereignisse aufgeteilt.
Verknüpfungen
lassen sich grundlegend in zwei Kategorien einteilen: In
Oder-Verknüpfungen,
bei denen der Fehler auftritt, falls eines der Ereignisse
auftritt, sowie in Und-Verknüpfungen,
bei denen der Fehler nur auftritt, falls alle Ereignisse
auftreten. Ein Block-Gatter führt zwischen einem Ereignis und der
entsprechenden Ursache eine Nebenbedingung ein. Die
Nebenbedingung muss zusätzlich zur Ursache vorhanden sein,
damit die Wirkung eintritt. Die Bedingung beschreibt
Ereignisse, die keine Fehler oder Defekte sind und im
Normalbetrieb auftreten.
Um einen großen Fehlerbaum anschaulich zu präsentieren,
können ganze Unterbäume durch ein Transfer-Symbol markiert
und separat analysiert werden. Die im Fehlerbaum definierten
Ursachen sind Zwischenereignisse, die weiter untersucht
werden, bis ein gewünschter Detaillierungsgrad erreicht wird.
Ursachen, die nicht weiter untersucht werden, sind Blätter im
Fehlerbaum. Blätter sind entweder Basisereignisse des Systems
oder Ereignisse, die für die Analyse (noch)
nicht detailliert genug beschrieben wurden (nicht untersuchte
Ereignisse). In der nachfolgenden Abbildung ist ein Beispiel
für einen Fehlerbaum dargestellt.
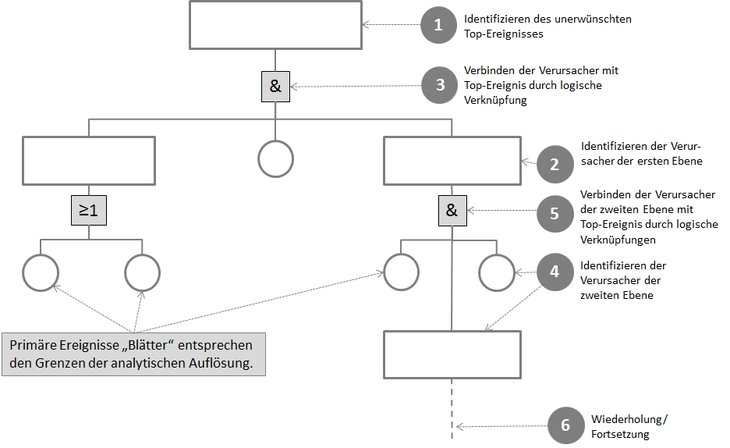
Vorgehensweise zur Konstruktion eines
Fehlerbaumes
In komplexen Systemen können zusätzlich auch
redundanzübergreifende Fehler auftreten. Dies sind
Fehlerquellen, die an mehreren Stellen des Fehlerbaums
auftreten und sich aufgrund der Systemstruktur nicht direkt in nur
einen Minimalschnitt zusammenfassen lassen. Diese sogenannten
"Gemeinsam verursachte Fehler" (GVA) bzw. Common Cause
Failure (CCF), erschweren die Anwendung
der Fehlerbaumanalyse.
Eine wesentliche Eigenschaft der Ereignisse in einem
Fehlerbaum ist, dass sie unerwünscht sind. Sie beschreiben
Fehlerzustände, Störungen oder Ausfälle. In der Praxis ist
der Einsatz von Fehlerbaum-Techniken oft auch gemeinsam mit
Szenariotechniken und mit Ereignisbaum-Techniken zu
beobachten. Letzterer Ansatz beobachtet all diejenigen
Faktoren, die zu einem Störfall führen können. Die
Darstellung erfolgt ebenfalls als Baum.
Nach Erstellung des Fehlerbaums wird bei der
quantitativen Fehlerbaumanalyse jedem
Basisereignis eine bestimmte Eintrittswahrscheinlichkeit für
den Ausfall zugewiesen. Daten für konkrete Ausfallsraten
können aus eigenen Untersuchungsreihen für die einzelnen
Basiskomponente
stammen, oder es wird bei handelsüblichen Bauelementen und
Komponenten auf freie Datenbanken wie das MIL-HDBK-217F oder
kommerzielle Datenbanken wie 217Plus zurückgegriffen. Die den
einzelnen Basiskomponenten zugewiesenen Ausfallraten λ lassen
sich im einfachen Fall einer Exponentialverteilung – dies
entspricht einer angenommenen zeitlich konstanten
Ausfallsrate über die Zeit t – mit der
Ausfallwahrscheinlichkeit P beschreiben.
Die Fehlerbaumanalyse wird
beispielsweise für die folgenden Fragestellungen eingesetzt:
In der Planung von Industrieanlagen, vor allem in der
Verfahrenstechnik, und im
vorbeugenden Brandschutz.
In der Software-Entwicklung wird sie verwendet, um die
Fehler von Programmen zu analysieren.
In der Flugsicherheit werden zur Bestimmung der
definierten SicherheitFehlerbaumanalysen
mittels Checklisten ausgeführt.
In der Produktentwicklung, vor allem in der
Automobilindustrie.
Im Rahmen der PSÜ
(Periodische Sicherheitsüberprüfung bzw. probabilistischen
Sicherheitsanalyse) für kerntechnische Anlagen, um die
Wahrscheinlich für den Ausfall eines sicherheitstechnischen
Systems angeben zu können.
Weiterführende Literaturhinweise:
Deutsches Institut für Normung (1981/1990) DIN 25424
Fehlerbaumanalyse (Fehlerbaumanalyse, Teil 1: Methode und
Bildzeichen, Teil 2: Handrechenverfahren zur Auswertung
eines Fehlerbaumes), Ausgabe 1981-09 bzw. Ausgabe 1990-04,
Berlin 1981/1990.
Romeike, F./Hager, P. (2013):
Erfolgsfaktor Risk
Management 3.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 3. Auflage, Wiesbaden 2013.
Vesely, W. et al (1981): Fault Tree Handbook, U.S.
Nuclear Regulatory Commission, Washington DC 1981.
Die (deterministische) Szenarioanalyse ist
im betriebswirtschaftlichen Kontext eine heutzutage verbreitete
Methode, die insbesondere im Bereich
Strategie/Unternehmensentwicklung, aber auch
im Risikomanagement,
als Instrument der Entscheidungsvorbereitung und -unterstützung
etabliert ist. Sie wird vorrangig bei zukunftsorientierten
Fragestellungen eingesetzt, kann aber auch bei der Auswahl einer
Alternative bei einer unmittelbar anstehenden Entscheidung
wirkungsvoll unterstützen.
Die Grundidee ist, einen alternativen Zustand zu beschreiben und
anhand dieser Beschreibung Konsequenzen auf eine zu untersuchende
Fragestellung abzuleiten. In aller Regel werden die so erhaltenen
Kenntnisse verwendet, um darauf aufbauend zu konkreten
Handlungsempfehlungen zu gelangen.
Formale Grundidee der Szenarioanalyse
Die Szenarioanalyse wurde im Jahr 1967 von
Herman Kahn und Anthony J. Wiener in die
Wirtschaftswissenschaften eingeführt. Sie definieren Szenario als
"a hypothetical
sequence of events constructed for the purpose of focussing
attention on causal processes and decision points.” [Kahn
/Wiener 1967, S. 6]: Kahn und Wiener weiter "They answer two
kinds of questions: (1) Precisely how might some hypothetical
situation come about, step by step? and (2) What alternatives
exist, for each actor, at each step, for preventing, diverting,
or facilitating the process.” [Kahn
/Wiener 1967, S. 6].
Kahn wollte – nach den Erfahrungen des Zweiten Weltkriegs – mit
Hilfe von Szenarien eingetretene Denkpfade verlassen und
unvorstellbare und undenkbare ("think the unthinkable")
Entwicklungen bei den Analysen berücksichtigen.
Für die Szenarioanalyse existieren je nach
Autor und Methodenschule verschiedene Vorgehensmodelle [vgl.
beispielsweise Götze 1993 oder von Reibnitz 1992], die jedoch
alle den drei Hauptschritten Analysephase, Extrapolation und
Szenariobildung sowie Auswertung und Transfer der Erkenntnisse
folgen. Hier soll ein aus acht Schritten bestehendes Vorgehensmodell
vorgestellt und kurz beschrieben werden, siehe dazu
nachfolgende Abbildung.
Der erste Schritt, das Festlegen der zu untersuchenden
Fragestellung, dient insbesondere zwei wichtigen Aspekten:
Klarheit zu erlangen, was genau zu untersuchen ist, sowie dem
gemeinsamen Verständnis darüber im Team. Bei dem
zweiten Aspekt geht es auch darum, eine gemeinsame Sprache zu
finden, was in einem interdisziplinär oder sogar intersektoral
zusammengesetzten Team nicht ganz
einfach, aber sehr wichtig ist. Nur das gemeinsame Verständnis
sichert, dass in der weiteren Analyse das
Team in die
gleiche Richtung arbeitet. Das Aufbauen dieses Verständnisses
lässt sich erfahrungsgemäß gut erreichen, wenn neben dem
Festlegen der Fragestellung die dazu notwendige Ausgangslage
oder Ist-Situation beschrieben wird. Hier wird anhand der
Prioritätensetzung schnell deutlich, wo signifikante
Unterschiede im Verständnis bestehen.
Einflussfaktoren beschreiben relevante Sachverhalte in Bezug
auf die zu untersuchende Fragestellung. Sie sind dadurch
gekennzeichnet, dass sie veränderlich sind und diese
Veränderung jeweils wichtig in Bezug auf die Fragestellung ist.
Das Identifizieren von Einflussfaktoren beginnt häufig als
interne Analyse unter dem
Einsatz von Kreativitätstechniken. Gegebenenfalls können hier
Strukturvorgaben – etwa das klassische politisch, ökonomisch,
sozial, technologisch, ökologisch – bei der Sammlung
potenzieller Einflussfaktoren helfen. Basierend auf diesen
Ergebnissen helfen vertiefende Literaturrecherchen und
Experteninterviews, die ermittelten Einflussfaktoren zu
verifizieren und zu ergänzen. Im Ergebnis dieses Schrittes
sollte zu den Einflussfaktoren ein gemeinsames Verständnis
vorherrschen, Duplikate sollten ebenso wie Ober- und
Unterbegriffe eliminiert sein. Um in der späteren Analyse
Missdeutungen zu vermeiden, sind Einflussfaktoren wertfrei zu
beschreiben. Wertfrei heißt, dass Worte wie stärker/schwächer,
mehr/weniger, gut/schlecht und so weiter nicht in der
Bezeichnung der Einflussfaktoren auftauchen, da ansonsten eine
Beeinflussung der Denkweise und bei der Bewertung der Szenarien
droht. In der Literatur wird hierfür auch der Begriff des
Deskriptors verwendet (vgl. beispielsweise Garfield 1997, S.
9].
Im nächsten Schritt sind die Einflussfaktoren entsprechend
ihrer Wichtigkeit in Bezug auf die Fragestellung zu
priorisieren. Ziel ist es, sich
in der weiteren Analyse auf die
wichtigsten Einflussfaktoren zu konzentrieren. Als Faustregel
sollten hiernach nicht mehr als zwanzig Einflussfaktoren üblich
bleiben. Dadurch wird die Komplexität der
weiteren Analyse reduziert.
Ohne diese Priorisierung besteht die Gefahr, in die
Komplexitätsfalle zu tappen und an der Analyse zu
scheitern. Als Instrumente kommen hier die
Einflussfaktorenanalyse, auch Vernetzungsmatrix oder
Papiercomputer von Vester genannt, oder auch eine
Einfluss-Unsicherheitsanalyse zum Einsatz.
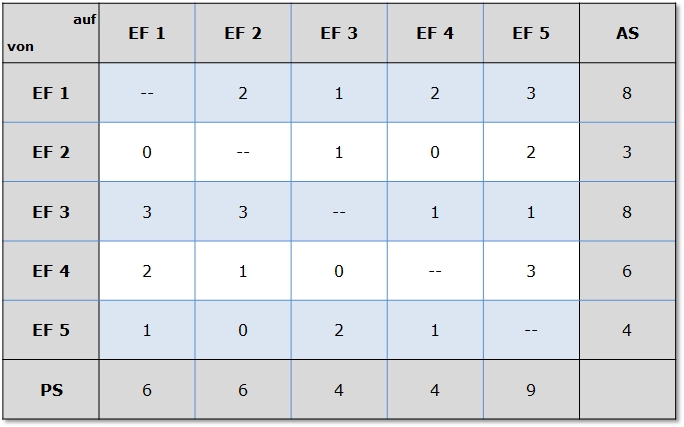
In der nachfolgenden Matrix ist beispielhaft eine
Einflussfaktorenanalyse (auch Vernetzungsmatrix oder
Papiercomputer von Vester genannt) skizziert.
Die Analyse der
Einflussfaktoren mit Hilfe einer Matrix erfolgt nach folgendem
Vorgehen:
Direkten Einfluss zwischen jeweils zwei Einflussfaktoren
(EF) quantifizieren (Skala beispielsweise von 0 – kein Einfluss
bis 3 – starker Einfluss);
Aktivsumme (AS) gibt an, wie stark der Einflussfaktor die
anderen Faktoren beeinflusst;
Passivsumme (PS) gibt an, wie
stark der Einflussfaktor durch andere Faktoren beeinflusst
wird;
Einflussfaktoren sind eher aktiv, wenn AS > PS, und eher
reaktiv, wenn AS < PS;
Einflussfaktoren sind kritisch (d. h. stark
vernetzt), wenn AS * PS groß ist, und
träge (d. h. wenig
vernetzt), wenn AS * PS kleine Werte
annimmt.
Zu beachten ist, dass bei diesem Schritt immer die Gefahr
besteht, dass relevante Bereiche für die weitere Analyse eliminiert
werden. Eine regelmäßige Kontrolle, ob hier versehentlich
falsche Einflussfaktoren gestrichen worden, ist daher im
weiteren Prozess
unerlässlich.
Im vierten Schritt werden die als realistisch erscheinenden
Ausprägungen je Einflussfaktor für die
weitere Szenarioanalyse festgelegt.
Quellen für diese Festlegung sind Studien, Experteninterviews,
Extrapolationen, Gruppendiskussionen und Intuition.
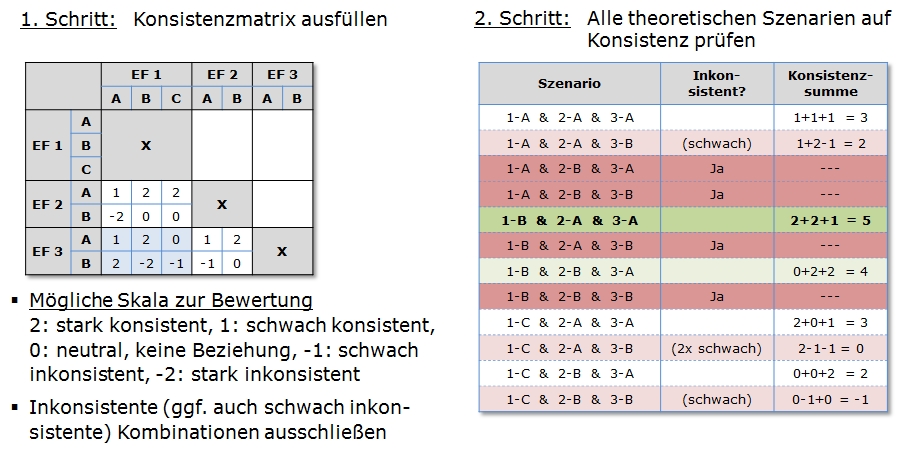
Mögliche Szenarien werden anschließend durch Kombination
verschiedener Ausprägungen der Einflussfaktoren gebildet. Für
diese ist zu untersuchen, ob sie in sich möglichst konsistent
sind, das heißt, ob die Ausprägungen der Einflussfaktoren sich
nicht widersprechen. Dies kann mit einer paarweisen Analyse oder mit
Hilfe einer Konsistenzmatrix erfolgen. Aus den konsistenten
Szenarien werden dann diejenigen ausgewählt, die im Folgenden
detailliert zu untersuchen sind. Die Schritte fünf und sechs
des Vorgehensmodells können gegebenenfalls auch in anderer
Reihenfolge durchgeführt werden, das heißt, zunächst wird
festgelegt, welche Szenarien detailliert untersucht werden
sollen. Bevor jedoch diese detaillierte Analyse erfolgt,
sind diese Szenarien auf Konsistenz zu prüfen und inkonsistente
Szenarien auszusortieren (vgl. nachfolgende Abbildung).
Konsistenzprüfung mittels Konsistenzmatrix
Die ausgewählten Szenarien werden in Hinblick auf die zu
untersuchende Fragestellung analysiert und die sich aus ihnen
ergebenden Konsequenzen abgeleitet. Oft ist es ratsam,
Störereignisse wie beispielsweise externe Schocks oder
Trendbrüche mit in diese Analyse
aufzunehmen, um so ein Gefühl für die Sensitivität
beziehungsweise Stabilität der Szenarien zu erhalten.
Änderungen im Ausmaß
einer Katastrophe sollten bei
dieser Sensitivitätsanalyse jedoch
außen vor bleiben, da mit ihnen häufig eine Veränderung des
gesamten Gefüges verbunden ist, also die getroffenen Annahmen
und berücksichtigen Wirkungszusammenhänge nicht mehr gelten.
Basierend auf den Konsequenzen werden Handlungsoptionen
gesammelt und diese ebenfalls auf ihren Einfluss hin
untersucht. Ergebnis sind dann konkrete Handlungsempfehlungen
für die untersuchte Fragestellung. Insbesondere für negative
Szenarien ist es zudem ratsam, Indikatoren zu identifizieren,
die den Eintritt des Szenarios ankündigen. All diese Ergebnisse
werden in einem sogenannten Szenario-Steckbrief
zusammengefasst.
Typische Anwendungsfälle
Szenarioanalysen sind dadurch gekennzeichnet, dass sie
bildhafte Darstellungen einer alternativen Situation
vermitteln. Diese Bilder werden in einem strukturierten
Prozess erarbeitet,
der zum Verständnis des Sachverhalts beiträgt. Dabei können
qualitatives Wissen und Annahmen mit quantitativen Fakten und
Prognosen kombiniert werden, so dass sich allein daraus ein
breites Anwendungsspektrum dieser Simulationsmethode ergibt.
Szenarioanalysen finden sich in betriebswirtschaftlichen Fragen
ebenso wie in volkswirtschaftlichen Untersuchungen, politischen
Analysen, technischen Fragestellungen oder militärischen
Umfeld, nur um einige Einsatzgebiete zu nennen.
Konkrete Anwendungen dieser flexiblen Simulationsmethode im
betriebswirtschaftlichen Kontext sind beispielsweise:
Analyse
alterativer beziehungsweise zukünftiger Zustände. Hierbei
geht es darum, mögliche Entwicklungen zu identifizieren, die
dahinter stehenden Annahmen zu explizieren und besonders
relevante Entwicklungen zu erkennen. Auswirkungen externer
und interner Einflüsse werden analysiert. Darüber hinaus
werden in diesem Prozess häufig
auch Unsicherheiten, Wissenslücken und Dilemmata aufgedeckt,
die im Rahmen der Entscheidungsfindung zu berücksichtigen
sind.
Zielbildung und Entscheidungsunterstützung. Existieren
lediglich vage Zielvorstellungen, können diese mit Hilfe
der Szenarioanalyse konkretisiert werden.
Im Fokus der Analyse stehen
Fragen wie: Wohin soll es gehen? Was soll konkret erreicht
werden? Wie soll dieses Ziel geschafft
werden? Dazu sind in aller Regel alternative
Handlungsoptionen zu entwickeln und zu bewerten, um
Entscheidungsprozesse aktiv und wirkungsvoll zu unterstützen.
Kommunikation von Sach- oder Problemlagen. Szenarien eignen
sich auch hervorragend, einzelne Entscheider oder auch breite
Bevölkerungsschichten über Themen und Problemlagen zu
informieren. Szenarien schaffen es durch ihre bildhafte und
gegebenenfalls pointierte Darstellung eines möglichen Zustands,
einen Sachverhalt greifbar und verständlich zu machen. Interne
wie öffentliche Debatten lassen sich dadurch anreichern.
Ausführungen und Erläuterungen können mit Hilfe von Szenarien
konkret und bildlich anstelle von vage und abstrakt vermittelt
werden.
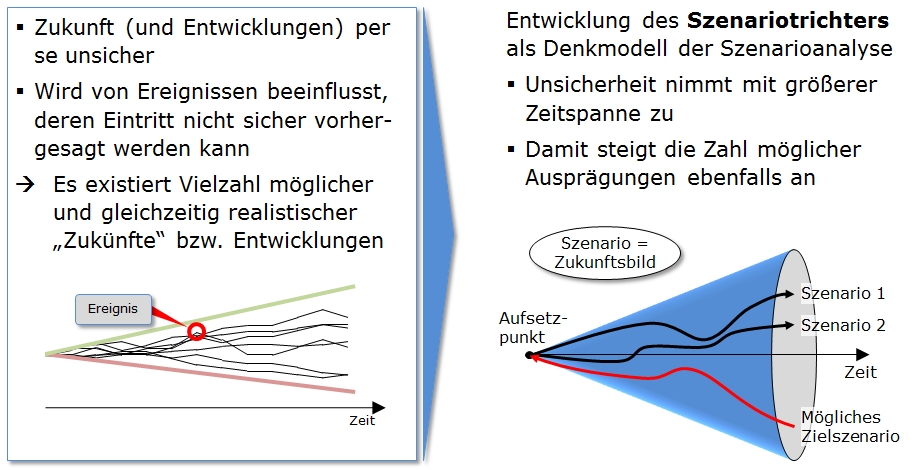
Szenariotrichter zur Visualisierung
Der Blick in die Zukunft ist selbstverständlich mit
Unsicherheiten verbunden. Daher wird das angestrebte Ergebnis
in Form eines Szenariotrichters visualisiert.
Visualisierung in Form eines Szenariotrichters
Den Ausgangspunkt beim Szenariotrichter bildet das
Trendszenario. Dieses Trendszenario stellt die zukünftige
Entwicklung unter der Annahme stabiler Umweltentwicklungen dar.
Da im Regelfall allerdings von instabilen Umweltbedingungen
ausgegangen werden muss, werden sowohl positive als auch
negative Entwicklungsmöglichkeiten berücksichtigt und im
Szenariotrichter abgebildet. Durch die zunehmende Unsicherheit
der potenziellen Zukunftsszenarien in der Zukunft verbreitert
sich die Spannweite über die Zeitachse. Das Extremszenario, das
die bestmögliche Entwicklung ("best case") aufzeigt, stellt das
obere Ende des Trichters dar. Das Extremszenario, das die
schlechteste Entwicklung ("worst case") abbildet,
stellt das untere Ende des Trichters ab. Die
Worst-Case-Szenarien können auch so genannte Stressszenarien
sein. Je breiter die Öffnung des Trichters, desto höher die
Unsicherheit der zukünftigen Entwicklung.
Weiterführende Literaturhinweise:
Garfield, E. (1997): A Tribute To Calvin N. Mooers, A
Pioneer Of Information Retrieval, in: The Scientist, Vol.11,
Ausgabe 6, 17. März 1997.
Götze, U. (1993): Szenario-Technik in der
strategischen Unternehmensplanung, Wiesbaden 1993.
Kahn, H./Wiener, A. J. (1967): The
Year 2000: A Framework for
Speculation on the Next Thirty-Three Years, New York 1967.
von Reibnitz, U. (1992): Szenario-Technik.
Instrumente für die unternehmerische und persönliche
Erfolgsplanung, Wiesbaden 1992.
Romeike, F./Hager, P. (2013):
Erfolgsfaktor Risk Management
3.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 3. Auflage, Wiesbaden 2013.
Die Monte-Carlo-Simulation wird
häufig für die Lösung komplexer Aufgaben wie beispielsweise zur
Messung finanzieller Risiken oder im Bereich Bandbreitenplanung
(EBIT@Risk, Cash Flow at Risk etc.)
vorgeschlagen. Es handelt sich dabei um
ein Simulationsverfahren auf Basis von
Zufallszahlen, dessen Name zunächst etwas kurios erscheinen mag.
Die genaue Herkunft der Bezeichnung für
dieses Simulationsverfahren ist nicht
bekannt, jedoch wurde in diesem Zusammenhang der Begriff "Monte
Carlo" das erste mal im zweiten Weltkrieg als Deckname für eine
geheime Forschung im Bereich des amerikanischen
Atomwaffenprogramms verwendet. Zwei Wissenschaftler haben 1942 in
Los Alamos für die Lösung komplexer Probleme
das Simulationsverfahren angewendet, welches
1949 als Monte-Carlo-Simulation bekannt
wurde. Vermutlich wurde der Name zuvor von einem 1862 in Monaco
gegründeten Casino abgeleitet, da ein Roulettetisch streng
genommen ebenfalls ein Zufallszahlengenerator ist.
Die Generierung von Zufallszahlen ist der wesentliche Unterschied
zwischen der Monte-Carlo-Simulation und
der Historischen Simulation.
Statt der Verwendung von historischen Wertänderungen wird die
Unsicherheit über das zukünftige Verhalten der Risikofaktoren mit
Zufallszahlen angegangen.
Dem Namen nach eine der bekanntesten Simulationsmethoden
dürfte
die Monte-Carlo-Simulation sein
(auch als
stochastische Szenarioanalyse bezeichnet;
im Gegensatz zur
deterministischen Szenarioanalyse). Das liegt
sicherlich zu einem nicht unerheblichen Teil am Namen Monte
Carlo, der in aller Welt durch das dort befindliche Casino
häufig mit Glücksspiel assoziiert wird. Eng damit verbunden ist
der Begriff der Wahrscheinlichkeit, und in der
Tat liefern die
mathematische Wahrscheinlichkeitstheorie und
die Statistik das wissenschaftliche Fundament dieser
Simulationsmethode.
Die Entwicklung der Methode ist eng verbunden mit den Namen der
beiden Mathematiker Stanislaw Ulam und John von Neumann. Sie
sollen während ihrer Arbeit zum Manhatten-Projekt am Los Alamos
Scientific Laboratory diese Methode verwendet haben, um
hochkomplexe physikalische Probleme nummerisch mit Hilfe
einer Simulation zu
lösen [vgl. Hubbard 2007, S. 46 sowie Grinstead/Snell 1997, S.
10-11]. Der Anekdote nach wurde als Codename Monte Carlo
verwendet. Die ersten wissenschaftlichen Publikationen zu
diesem Verfahren erschienen Ende der 1940er Jahre [vgl.
Ulam/Richtmyer/von Neumann 1947]. Mit dem zur damaligen Zeit
parallelen Aufkommen elektronischer Computer fand
die Monte-Carlo-Simulation zunächst
in der Wissenschaft, später auch in der Wirtschaft ihre
Verbreitung.
Eine der ersten Monte-Carlo-Simulationen der Geschichte hat
jedoch bereits der französische Naturforscher Georges Louis
Leclerc de Buffon im 18. Jahrhundert durchgeführt [vgl.
Kaiser/Nöbauer 1998, S. 185 und S. 286]. In seinem unterdessen
berühmten Nadelexperiment untersuchte er, mit
welcher Wahrscheinlichkeit eine zufällig
geworfene Nadel die Linien eines parallelen Rasters kreuzt.
Diese Wahrscheinlichkeit lässt sich
analytisch ermitteln, sie ist unter anderem abhängig von der
mathematischen Naturkonstante π. Dieses Verfahren kann jedoch
auch umgekehrt benutzt werden, um eben dieses π zu ermitteln.
Durch den Zufallscharakter jedes einzelnen Nadelwurfs beruht
dieses Verfahren auf dem Prinzip der Monte-Carlo-Methode.
Die grundlegende Idee der Monte-Carlo-Methode ist es, für
zufällig gewählte Parameter über die entsprechenden
Zusammenhänge (Ursache-Wirkungsgeflecht) die zugehörigen
Ergebnis- oder Zielgrößen zu ermitteln. Das zur Ermittlung der
Zielgrößen verwendete Modell ist in der
Regel deterministischer Natur, das heißt, mit dem Festlegen der
Parameter sind die Zielgrößen eindeutig bestimmt. Allerdings
sind die Zielgrößen durch den Zufallscharakter der Parameter im
Prinzip wiederum zufällige Größen. Jedoch kann im Allgemeinen
davon ausgegangen werden, dass eine hinreichend große Anzahl so
ermittelter Zielgrößen einen guten Näherungswert für die
tatsächlichen Werte dieser Zielgrößen darstellt (genau genommen
sind nicht die tatsächlichen Werte, sondern die Erwartungswerte
der Zielgrößen gemeint. Mathematisches Fundament dieses
Vorgehens sind das Gesetz der großen Zahlen,
der Hauptsatz der Statistik, siehe Satz von Gliwenko, sowie der
zentrale Grenzwertsatz). Die Monte-Carlo-Methode ist damit ein
Stichprobenverfahren. Auf Grund der zufälligen Auswahl der
Parameter hat sich ebenfalls der Begriff der
stochastischen Simulation etabliert
[vgl. vertiefend Romeike/Hager 2013, S. 339 ff. sowie
Romeike/Spitzer 2013, S. 101 ff.].
Das Vorgehen bei einer Monte-Carlo-Simulation wurde
von Metropolis und Ulam in einem Artikel beschrieben, der im
Jahre 1949 im Journal of the American Statistical Association
erschienen ist. Darin beschreiben beide Wissenschaftler das
Vorgehen bei der Monte-Carlo-Methode durch zwei Schritte: "(1)
production of 'random' values with their frequency distribution
equal to those which govern the change of each parameter, (2)
calculation of the values of those parameters which are
deterministic, i.e., obtained algebraically from the others."
[Metropolis/Ulam 1949, S. 335-341].
Diese aus heutiger Sicht simple Idee, die Eingangsparameter
einer Simulation als
Zufallsgrößen zu betrachten, kann auch mit anderen
Simulationsansätzen kombiniert werden. So sind stochastische
Szenarioanalysen keine Seltenheit, aber auch für nahezu alle
weiter unten erläuterten Simulationsmethoden ist die Verwendung
stochastischer Parameter heutzutage eine gängige Praxis.
Illustration der Methode
An dem durch Metropolis und Ulam beschriebenen Vorgehen hat
sich in den letzten etwa 60 Jahren nicht viel geändert.
Illustriert werden soll das Vorgehen an folgendem Beispiel
[vgl. Romeike/Spitzer 2013, S. 103 f.]: Ein Servicetechniker
betreut zwei Kunden. Kunde A benötigt
mit einer Wahrscheinlichkeit von 20
Prozent die Unterstützung des Technikers, während Kunde B lediglich
mit einer Wahrscheinlichkeit von 5
Prozent auf Hilfe angewiesen ist. Gesucht ist
die Wahrscheinlichkeit, dass beide Kunden,
die stochastisch unabhängig voneinander agieren, gleichzeitig
den Servicetechniker um Hilfe bitten (die Lösung ist in
diesem einfachen Fall auch analytisch ermittelbar,
die Wahrscheinlichkeit eines
gleichzeitigen Hilferufs beträgt 20 % * 5 % = 1 %).
Soll dieses Beispiel mit Hilfe
der Monte-Carlo-Simulation gelöst
werden, so wird zunächst eine zufällige Situation erzeugt und
für diese geprüft, ob beide Kunden den Techniker um Hilfe
bitten. Dies geschieht dadurch, dass zunächst Zufallszahlen
für A und B ermittelt werden und jeweils gemäß der
angegebenen Wahrscheinlichkeit ein
Servicebedarf festgestellt wird. Da gängige
Zufallszahlengeneratoren Zufallszahlen zwischen 0 und 1
generieren, kann die Zuordnung Servicebedarf erfolgen, wenn
die Zufallszahl des Kunden A kleiner als 0,2 und die des
Kunden B kleiner als 0,05 ist. Damit ist der erste Schritt im
Vorgehen von Metropolis und Ulam bereits erledigt.
Anschließend ist die Zielgröße der Simulation zu
ermitteln, was im vorliegenden Fall bedeutet, dass beide
Kunden gleichzeitig einen Servicebedarf (beziehungsweise
keinen gleichzeitigen Servicebedarf) anmelden. Dies
entspricht bereits dem zweiten Schritt des von Metropolis und
Ulam beschriebenen Vorgehens.
Diese Abfolge der Schritte 1 und 2 wird nun so lange
wiederholt, bis die sich ergebende Verteilung der Zielgröße
eine stabile Verteilung zeigt. Wie aus nachfolgender
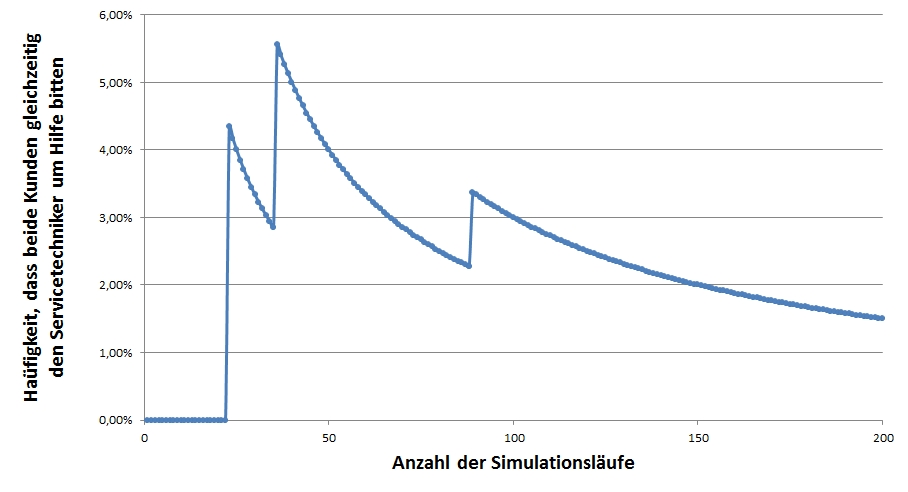
Abbildung ersichtlich, konvergiert die Zielgröße mit
steigender Anzahl an Simulationsläufen gegen den bereits
analytisch ermittelten Wert von 1 Prozent.
Beispielhafter Ablauf der beschriebenen
Monte-Carlo-Simulation
Typische Anwendungsfälle
Generell lassen sich zwei Problemgruppen unterscheiden, bei
denen die Monte-Carlo-Methode angewendet werden kann. Mit ihrer
Hilfe können einerseits Problemstellungen deterministischer
Natur, die eine eindeutige Lösung besitzen, bearbeitet werden.
Auf der anderen Seite sind aber auch Fragen, die sich der
Gruppe stochastischer Problemstellungen zuordnen lassen, für
eine Monte-Carlo-Simulation ein
geeignetes Anwendungsfeld. Zum letzten gehört beispielsweise
das im vorherigen Absatz beschriebene Beispiel.
Ein typisches und weit bekanntes Anwendungsbeispiel der ersten
Problemgruppe ist die Berechnung von Integralen, beispielsweise
zur Ermittlung der Zahl π, die hier zum Verständnis der Methode
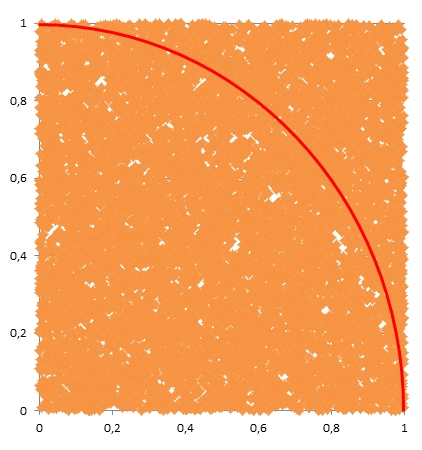
kurz dargestellt werden soll. Bei der auch "Hit or Miss"
benannten Methode werden eine große Anzahl zufälliger
Wertepaare (x, y) ermittelt,
wobei x und yjeweils
gleichverteilte Zufallszahlen zwischen 0 und 1 sind.
Anschließend wird gezählt, wie viele dieser Wertepaare
innerhalb des durch x2+y2 < 1
beschriebenen Viertelkreises befinden. Diese Anzahl der
"Treffer" (Hit) bezogen auf die Anzahl aller zufälligen
Wertepaare (x, y) ist ein Näherungswert für π/4.
Kennzeichnend für dieses Vorgehen ist es, dass das Ergebnis
faktisch aus einer zufälligen Stichprobe an
Wertepaaren ermittelt wird, obwohl eine analytisch exakte
Ermittlung ebenfalls möglich wäre.
Ermittlung der Zahl π mit Hilfe der
Monte-Carlo-Simulation
Der mit dem Einsatz der Monte-Carlo-Methode erzielte Vorteil
liegt in einer sehr schnellen und einfachen Ermittlung des
Ergebnisses. Dafür werden dann durch das Näherungsverfahren
entstehende Genauigkeitsverluste im Vergleich zu einer exakten
Ergebnisermittlung, die häufig wesentlich aufwändiger und
deutlich zeitintensiver ist, bewusst in Kauf genommen. Und so
findet die Monte-Carlo-Methode in diesem Problemfeld neben der
Berechnung von bestimmten Integralen beispielsweise ebenfalls
Anwendung bei der Lösung gewöhnliche und partielle
Differentialgleichungen, insbesondere in der Teilchenphysik.
Die zweite Problemgruppe stochastischer Fragestellungen ist
dadurch gekennzeichnet, dass die Eingangsparameter und daraus
resultierend auch die Zielgrößen stochastischer Natur sind.
Damit ist gemeint, dass statt eines wohldefinierten Wertes für
den Parameter im einfachsten Fall mehrere mögliche diskrete
Werte, jeweils versehen mit einer Eintrittswahrscheinlichkeit,
gegeben sind. Im Allgemeinen stammen die Parameter sogar aus
einem Kontinuum an Werten, für das
eine Wahrscheinlichkeitsdichte, eine sogenannte
Verteilungsfunktion, bekannt ist oder gar nur geschätzt wird.
Die mit diesen Parametern in Verbindung stehenden Zielgrößen
sind dann ebenfalls stochastischer Natur, was heißt, dass sie
mittels einer Verteilungsfunktion beschreibbar sind.
Bei geringer Komplexität der Zusammenhänge
zwischen Parametern und Zielgrößen und gleichzeitig einfachen
Verteilungsfunktionen der Parameter können die
Verteilungsfunktionen der Zielgrößen meist noch analytisch
ermittelt werden. Schnell ist jedoch eine Grenze erreicht, wo
die analytische Ermittlung zu aufwändig wird oder auch gar
nicht mehr möglich ist. Hier kommt dann die Monte-Carlo-Methode
zum Einsatz. Wie bereits oben beschrieben werden dazu auf Basis
der Verteilungsfunktionen zufällige Parameter ausgewählt und
für diese werden die zugehörigen Zielgrößen ermittelt. Durch
ein vielfaches Wiederholen dieser Ermittlung der Zielgrößen
wird für diese eine Häufigkeitsverteilung bestimmt, die eine
Näherung für die tatsächliche Verteilungsfunktion der
Zielgrößen darstellt.
Aus einer betriebswirtschaftlichen Sicht können somit alle
Fragen untersucht werden, die
entweder aufgrund der Vielzahl ihrer Einflussgrößen nicht
mehr exakt analysiert werden (können) und bei denen daher auf
eine Stichprobe für
die Analyse
zurückgegriffen wird;
oder bei denen die Eingangsparameter Zufallsgrößen sind.
(Auch die Optimierung von Prozessen oder Entscheidungen bei
nicht exakt bekannten Parametern gehören zu dieser Gruppe.)
Diese beiden Kriterien treffen nun auf eine Vielzahl
betriebswirtschaftlicher Entscheidungen zu, dementsprechend
finden sich eine ganze Reihe konkreter Anwendungsfälle von
Monte-Carlo-Simulationen in betriebswirtschaftlichen
Fragestellungen:
Die Stabilitätsanalyse von Algorithmen und Systemen. Hier
werden Monte-Carlo-Simulationen genutzt, um beispielsweise in
der Kostenrechnung die Auswirkungen veränderter Aufteiler in
der Kostenträgerrechnung auf die Produktkosten zu ermitteln.
Die Aggregation von Einzelrisiken
eines Unternehmens zu einem unternehmerischen Gesamtrisiko.
Hierbei wird für jedes Einzelrisiko eine
Wahrscheinlichkeitsverteilung geschätzt, um daraus mit Hilfe
der Monte-Carlo-Simulation ein
aggregiertes Risiko zu ermitteln. Die
entstehende Verteilungsfunktion wird in aller Regel auf
einzelne kommunizierbare Kennzahlen,
etwa Erwartungswert oder ausgewählte
Quantilswerte – wie etwa dem Value at
Risk oder das Risikokapital –
verdichtet.
Ein wichtiger Schritt zu einer risikoorientierten
Weiterentwicklung des Controllings stellt die so genannte
"Szenario-Planung"
dar. Hierbei werden zukünftige EBIT-Entwicklungen unter
Berücksichtigung von Risiken (EBIT-at-Risk) simuliert.
Hierbei liegt die Erkenntnis zu Grunde, dass Szenarien und
Simulationen bewährte Instrumente aus der Praxis darstellen,
um sich mit zukünftigen potenziellen Entwicklungen zu
beschäftigen. Eine risikoorientierte Planung verfolgt das
Ziel, die
traditionelle "einwertige" Planung mit einem Erwartungs- oder
Zielwert durch eine realistischere Planung unter Nutzung von
Verteilungsfunktionen ("stochastische Planung") zu ersetzen,
die sowohl das erwartete Ergebnis als auch den Umfang
möglicher Abweichungen (Risiken) beschreiben kann [vgl.
vertiefend Romeike 2010, S. 13-19 sowie Romeike/Hager 2014].
Die Vorhersage von Entwicklungen, die selbst durch
zufällige Ereignisse beeinflusst werden (sogenannte
stochastische Prozesse).
Klassische Beispiele sind die Simulationvon
Börsen- oder Währungskurse, die auf die Dissertation des
französischen Mathematikers Louis Bachelier zurück geht.
Basierend auf eigenen Annahmen, gegebenenfalls begründet mit
Beobachtungen aus der Vergangenheit, werden hierbei derartige
Entwicklungen simuliert und ihre Auswirkungen auf
betriebswirtschaftliche Größen analysiert.
Die Optimierung von eigenen Entscheidungen, die auf
unsicheren Annahmen beruhen. Hierunter fallen beispielweise die
Gewinnmaximierung bei unsicherem Absatz im
Newsvendor-Modell. Im
Newsvendor-Modell kauft ein
Zeitungsjunge morgens eine Anzahl an Zeitungen, um sie
anschließend an seine Kunden weiter zu verkaufen. Nicht
verkaufte Zeitungen kann er nur mit Verlust zurückgeben, so
dass sich für ihn die Frage seiner optimalen Einkaufsmenge
stellt. Ist die Marktnachfrage eine stochastische Größe, so
ist die Maximierung seines
Gewinnerwartungswerts ist zwar formal-analytisch möglich.
Jedoch ist damit keinesfalls die optimale Einkaufsmenge exakt
ermittelbar, dies geht nur bei einfachen stochastischen
Nachfragefunktionen (für eine Lösung mit Hilfe von
Monte-Carlo-Simulationen siehe beispielsweise Microsoft 2003)
ebenso wie die Analyse und
Optimierung von Investitionsvorhaben in Hinblick auf die
Erfolgswahrscheinlichkeit oder Finanzierung der Investition
[vgl. beispielsweise Duscher/Meyer/Spitzner 2012 sowie
Romeike/Hager 2009 sowie Romeike/Hager 2013].
Weiterführende Literaturhinweise:
Duscher, I./Meyer, M./Spitzner, J. (2012):
Volatilität kalkulieren und steuern im Sinne eines
wertorientierten Investitionscontrollings, in: Zeitschrift
für Controlling und
Management, Sonderheft 2, Juli 2012, S. 46-51.
Grinstead, C. M./Snell, J. L. (1997):
Introduction to Probability, American Mathematical Society,
1997.
Hubbard, D. (2007): How to Measure Anything: Finding the
Value of Intangibles in Business, Hoboken
2007.
Kaiser, H./Nöbauer, W. (1998): Geschichte der Mathematik,
Wien 1998.
Metropolis, N. C./Ulam, S. (1949): The Monte Carlo Method,
Journal of the American Statistical Association, Vol. 44, No.
247, (Sep. 1949), S. 335-341.
Romeike, F. (2010): Risikoadjustierte Unternehmensplanung –
Optimierung risikobehafteter Entscheidungen basierend auf
stochastischen Szenariomethoden, in: Risk, Compliance &
Audit, 06/2010, S. 13-19.
Romeike, F./Spitzner, J. (2013): Von
Szenarioanalyse bis Wargaming, Betriebswirtschaftliche
Simulationen im Praxiseinsatz, Weinheim 2013.
Romeike, F./Hager, P. (2009):
Erfolgsfaktor Risk Management
2.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 2. Auflage, Wiesbaden 2009.
Romeike, F./Hager, P. (2013):
Erfolgsfaktor Risk Management
3.0 – Methoden,
Beispiele, Checklisten: Praxishandbuch für Industrie und
Handel, 3. Auflage, Wiesbaden 2013.
Ulam, S./Richtmyer, R. D./von Neumann, J. (1947):
Statistical methods in neutron diffusion, in: Los Alamos
Scientific Laboratory report LAMS-551; Los Alamos 1947.
System
Dynamics (SD) oder Systemdynamik ist eine von Jay W.
Forrester an der Sloan School of Management des MIT entwickelte
Methodik zur ganzheitlichen Analyse und (Modell-) Simulation komplexer
und dynamischer Systeme. Anwendung findet sie insbesondere
im sozio-ökonomischen Bereich. So können die Auswirkungen von
Management-Entscheidungen auf die Systemstruktur und das
Systemverhalten (beispielsweise Unternehmenserfolg) simuliert und
Handlungsempfehlungen abgeleitet werden. In der Praxis findet die
Methodik insbesondere bei der Gestaltung von Lernlabors und der
Hinterlegung von Balanced Scorecards mit Strategy Maps
Verwendung. Die Erarbeitung solcher Systeme erfolgt mittels
qualitativer und quantitativer Modelle auf Basis von
Ursache-Wirkungsbeziehungen.
System
Dynamics lieferte die grundlegende Methodik
zur Simulation des
Weltmodells World3, das für die Studie "Die Grenzen des
Wachstums" im Auftrag des Club of Rome erstellt wurde.
Die heute verwendeten Werkzeuge beispielsweise
im Risikomanagement treffen
immer häufiger auf Grenzen, da sie mit
der Komplexität der Strukturen und
Prozesse der realen
Welt nicht adäquat umgehen können. Bereits Anfang der 1950er
Jahre hatte Jay Wright Forrester an der Sloan School of
Management des Massachusetts Institute of Technology
"System
Dynamics" (SD) als Methodik zur ganzheitlichen Analyse und
(Modell-)Simulationkomplexer
und dynamischer Systeme entwickelt.
Ausschlaggebend für Forresters Analysen am Massachusetts
Institute of Technology war eine Zusammenarbeit mit dem
US-amerikanischen Konzern General Electric. Es fiel Forrester
auf, dass ihm bei der Suche nach Gründen für die nicht optimale
Auslastung eines Werkes sein Wissen als Ingenieur half. Die
Situation von General Electric wurde in einem formalen Modell abgebildet
und ihre zeitliche Entwicklung mit Hilfe eines Computers
simuliert. Dabei kristallisierte sich neben den bekannten
Geschäftszyklen die Struktur eines schwingenden, instabilen
Systems heraus, bei dem trotz konstanter Auftragseingänge
instabile Beschäftigungsverhältnisse als Konsequenz
vorliegender "policies" auftraten. Forrester veröffentlichte
basierend auf diesen Erkenntnissen sein Werk "Industrial
Dynamics" [Forrester 1961], in dem er formulierte: "Industrial
Dynamics is the investigation of the information-feedback
character of industrial systems and the use of models for the
design of improved organizational form and
guiding policy." [Forrester 1961, S. 13].
Ausgehend von der Erkenntnis, dass mit Hilfe dieser Methode
sämtliche soziale Systeme modelliert und diese Modelle
anschließend simuliert werden können, lag es nahe, den
speziellen Begriff "Industrial Dynamics" in den allgemeineren
Ausdruck "System
Dynamics" umzubenennen. System
Dynamics war auch die grundlegende Methodik
zur Simulation des
Weltmodells World3, einer Studie zur Zukunft der
Weltwirtschaft, die der Club of Rome in Auftrag gegeben hatte
[Meadows/Meadows/Randers/Behrens III 1972].
Ausgangspunkt für die Entwicklung von System
Dynamics bildete die wissenschaftliche Diskrepanz
zwischen Ansätzen der klassischen Ökonometrie sowie einer
ganzheitlichen Analyse und
(Modell-) Simulation komplexer
und dynamischer Systeme [vgl. Forrester 1961 sowie Forrester
1971]. System
Dynamics ist daher als eine Methodik zur Modellierung, Simulation,
Analyse und
Gestaltung von dynamisch-komplexen Sachverhalten in
sozioökonomischen Systemen zu verstehen. Dynamische und
komplexe Systeme – wie eben auch Unternehmen – zeichnen sich
unter anderem sowohl durch verzögerte Ursache-Wirkungs-Effekte
als auch durch Rückkopplungsbeziehungen zwischen einzelnen
Variablen aus. Klassische ökonometrische Modelle sind
grundsätzlich stochastischer Art, da zur
Schätzung die Verfahren der schließenden (induktiven) Statistik
angewandt werden. Nicht alle Variablen eines ökonometrischen
Modells sind direkt beobachtbar
(latente Variablen). Beobachtbar sind die exogenen (Input) und die
endogenen (Output) Variablen.
System
Dynamics beschäftigt sich mit dem Verhalten von
gelenkten Systemen im Zeitablauf. Es verfolgt das Ziel, Systeme mit
Hilfe qualitativer und quantitativer Modelle nicht nur zu
beschreiben, sondern auch zu verstehen, wie
Rückkopplungsstrukturen das Systemverhalten determinieren. Der
Begriff System – aus dem
Griechischen für "das Gebilde" und "das Verbundene" –
bezeichnet hierbei eine Gesamtheit von Elementen, die so
aufeinander bezogen beziehungsweise miteinander verbunden sind
und in einer Weise wechselwirken, dass sie als eine aufgaben-,
sinn- oder zweckgebundene Einheit angesehen werden können.
Coyle definiert daher System
Dynamics wie folgt: "System
Dynamics deals with the time-dependent
behavior of managed systems with the aim of describing the
system and understanding, through qualitative and quantitative
models, how information feedback structures and control
policies through simulations and optimization." [Coyle 1996, S.
10].
System
Dynamics bildet komplexe Strukturen modellseitig ab
und ermöglicht Entscheidern, die Beziehungen zwischen einzelnen
Systemkomponenten besser zu identifizieren.
Von Komplexität wird immer dann
gesprochen, wenn ein System in seiner
Zusammensetzung kompliziert ist und dazu noch seinen Zustand im
Zeitablauf ändert. Komplexität bezeichnet
die aus den Beziehungen hervorgehende Vielfältigkeit von
Zuständen und Zustandskonfigurationen in Systemen während einer
Zeitspanne [Ulrich/Probst 1991, S. 58]. Dabei ist
die Komplexität umso größer, je mehr
Elemente vorhanden und je mehr diese voneinander abhängig sind.
System
Dynamics unterstützt die Entwicklung formaler,
mathematischer Modelle, um das Systemverhalten zu simulieren.
Aufgrund der geschlossenen Struktur von System
Dynamics sind in derartigen Modellen keine exogenen
Variablen enthalten. Lediglich die Anfangswerte der
Zustandsvariablen (Level) und die Parameter (constants), als
konstante Hilfsgrößen, werden exogen in das isolierte System vorgegeben.
Dabei sind die Zustandsvariablen aufgrund der interdependenten
Struktur tatsächlich endogen.
Forrester lehnt eine Steuerung eines
Modellsystems durch exogene Variablen ab, da sich alle
ökologischen, sozialen und politischen Vorgänge in einem
geschlossenen (Sub-)System abspielen
[vgl. Forrester 1972, S. 137 ff.]. Der Reproduktion der
entsprechenden Variablen innerhalb der Rückkopplungsstruktur
des geschlossenen Systems misst Forrester eine sehr große
Bedeutung bei [vgl. Forrester 1961, S. 348].
Ein wichtiges Kriterium von System
Dynamics ist, dass auch nicht-lineare Beziehungen
zwischen den Variablen simuliert werden können. In der
klassischen Ökonometrie werden dagegen primär lineare Modelle
betrachtet beziehungsweise nicht-lineare Funktionstypen in
lineare transformiert. Lehmann merkt hierzu kritisch an, dass
die Ökonometrie "ihre Modellstruktur der mathematischen
Lösungstechniken" [Lehmann 1975, S. 40] anpasse.
Illustration der Methode
System
Dynamics verfolgt das Ziel, das
Verhalten eines komplexen Systems zu erklären. Um dieses
Ziel zu
erreichen, werden relevante Systemstrukturen modelliert. In
einem System-Dynamics-Modell werden
hierzu vier konstituierende Elemente dynamischer
sozio-ökonomischer Systeme erfasst:
Bestandsgrößen (level, stock): Bestandsgrößen
sind Systemvariablen, die den aktuellen Zustand eines
dynamischen Systems beschreiben, beispielsweise die
aktuelle Risikosituation oder den aktuellen Lagerbestand.
Kausale Feedbackbeziehungen (feedback
loops): Hierbei wird zwischen positiven
(reinforcing loops) und negativen (balancing loops)
Polaritäten unterschieden. Feedback ist die Rückführung von
Informationen über den aktuellen Zustand eines Systems auf
dessen Eingang. Die Interaktion von Feedbackbeziehungen
regelt das Verhalten eines Systems.
Wirkungsverzögerungen (delay): Diese sind
dadurch gekennzeichnet, dass Ursache und Wirkung zeitlich
voneinander getrennt sind.
Nichtlinearitäten (nonlinearities): Die
Besonderheit von System
Dynamics liegt darin, dass auch
Nichtlinearitäten berücksichtigt werden können. Ein
System ist
immer dann nichtlinear, wenn Anpassungen in der
Ausbringungsmenge nicht proportional zu Änderungen in der
Eingabemenge sind.
Um ein System
Dynamics Modell zu
definieren, wird nach einer grundsätzlichen Beschreibung des
Modells in einem zweiten Schritt ein kausales
Rückkopplungsdiagramm (Causal Loop Diagram, CLD) erstellt. In
weiteren Schritten folgen die Konvertierung der Beschreibung
in Bestandsgrößen- und Flussdiagramme (Stock and Flow
Diagram, SFD). Die anschließende Simulation des
Modells unterstützt das Entwerfen von alternativen "policies"
und Strukturen sowie die Diskussion dazu. So können geeignete
"policy"- und Strukturveränderungen identifiziert
werden. Ein typisches Ursache-Wirkungsgeflecht eines System-Dynamics-Modells
zeigt die nachfolgende Abbildung.
System
Dynamics wird vor allem zur Modellierung
komplexer und dynamischer Systeme eingesetzt. Die Methodik
bietet die Möglichkeit, komplexe Ursache-Wirkungsgeflechte
granular abzubilden und anschließend zu analysieren. Die
Auswirkungen singulärer Entscheidungen werden so häufig erst in
ihrer umfänglichen Tragweite transparent und auch unter
langfristigen Gesichtspunkten begründbar. So können System-Dynamics-Analysen
dazu führen, dass ursprünglich für richtig befundene
Entscheidungen und Entscheidungsregeln revidiert werden müssen,
da aus einer ganzheitlichen Systemanalyse zuvor unbedachte
Effekte ersichtlich werden.
System
Dynamics ist ein methodischer Ansatz, mit dessen
Hilfe ein System ganzheitlich
betrachtet wird. Daher liegt der Schwerpunkt
von System
Dynamics auf Analysen in einer nicht-atomistischen
Sichtweise. (Diese Metasicht wird häufig auch als Kritik
gegenüber System
Dynamics vorgebracht.) Mit dieser Makroperspektive
wird der Fokus der Analyse auf die ein
System
determinierenden Elemente und deren Interaktion gelenkt.
Dahinter steckt die Logik, dass ein komplexes und dynamisches
System nur dann
verstanden werden kann, wenn
die Komplexität möglichst adäquat
abgebildet wird. Um die
reale Komplexität erfassen zu können,
bedarf es darüber hinaus einer
nicht-linearen Art des Denkens. Dieser
Theorieansatz des nicht-linearen Denkens kann unter dem Begriff
"systems thinking" subsumiert werden [vgl. Sterman 1994, 2-3,
S. 291 und Ossimitz 1995, S. 6].
Vor diesem Hintergrund sind typische Anwendungen im
betriebswirtschaftlichen Kontext:
Bevorstehende Entscheidungssituationen sind durch
Rückkopplungen und zeitliche Verzögerungen gekennzeichnet.
Deren Auswirkungen können mit Hilfe eines System-Dynamics-Ansatzes
sichtbar gemacht werden. Mögliche Entscheidungsalternativen
können daher analysiert und darauf aufbauend eine optimale
Auswahl getroffen werden.
Erklärungsmodelle von Systemverhalten. Um scheinbar
überraschende Effekte zu erklären, wird System
Dynamics in der Aus- und Weiterbildung eingesetzt.
Hierzu werden Modelle eines Systems nachgebaut und mit
einer Art spielerischen Erlebens werden
die Konsequenzen von Entscheidungen transparent gemacht. Die
Analyse der
relevanten Systemkomponenten im Nachgang von simulierten
Entscheidungssituationen zeigt die systemischen
Wirkzusammenhänge auf. Beispiele derartiger Erklärungsmodelle
sind Fish Banks [vgl. Whelan 1994 sowie Ford 1999] oder das
Beer Game [vgl. Sterman 1989 sowie Sterman 1984].
Weitere betriebswirtschaftliche Anwendungsgebiete sind
Unternehmensentwicklung [vgl. Mass/Berkson 1995,
Glucksman/Morecroft 1998 sowie Lyneis 1980],
Energieversorgung und –preisgestaltung [vgl. Naill 1992] und
das Managementtraining [Rosenørn/Kofoed 1998 sowie
Warren/Langley 1999]. Darüber hinaus wird die Methodik auch
erfolgreich zur Untersuchung auf Gebieten wie Medizin [vgl.
Dangerfield 1999], Fischerei [Hannon/Ruth 1994], Psychiatrie,
Volkswirtschaften [vgl. Heij/Schumacher/Hanzon/Praagman 1997],
städtischem Wachstum [vgl. Forrester 1969],
Umweltverschmutzung, Bevölkerungswachstum [Dörner 1989] sowie
Pädagogik [vgl.
Coyle 1999 sowie Milling 1999] herangezogen.
Weiterführende Literaturhinweise:
Coyle, R. G. (1996): System Dynamics
modelling – A practical approach, London 1996.
Coyle, R. G. (1999): System dynamics
at Bradford University: a silver jubilee
review, in: Journal of the Operational Research Society, 50,
1999, 4, S. 296-301
Dangerfield, B. C. (1999): System dynamics
applications to European health care issues, in: Journal of
the Operational Research Society, 50, 1999, 4, S. 345-353.
Dörner, D. (1989): Die Logik des Misslingens. Strategisches
Denken in komplexen Situationen, Reinbek 1989.
Forrester, J. W. (1961):
Industrial Dynamics, Waltham/MA 1961.
Ford, F. A. (1999): Modeling the Environment: An
Introduction to System Dynamics
Models of Environmental Systems, Island Press, Washington DC
1999.
Forrester, J. W. (1969):
Urban dynamics, Portland 1969.
Forrester, J. W. (1971):
Counterintuitive behavior of social systems, in: Technology
Review. 73(3) 1971, S. 52-68.
Forrester, J. W. (1972):
Grundzüge einer Systemtheorie, Wiesbaden 1972.
Glucksman, M./Morecroft, J. (1998):
Managing metamorphosis, in: The McKinsey Quarterly, 34, 1998,
2, S. 118-129.
Hannon, B. M./Ruth, M. (1994): Dynamic modeling, Springer,
New York/Berlin 1994.
Heij, C./Schumacher, H./Hanzon, B./Praagman, K. (1997)
[Hrsg.]: System dynamics
in economic and financial models, John Wiley and Sons,
Chichester/New York 1997.
Lehmann, G. (1975): Wirtschaftswachstum im Gleichgewicht,
Stuttgart 1975.
Lyneis, J. M. (1980):
Corporate planning and policy design: a system dynamics
approach, MIT Press, Cambridge/London 1980.
Mass, N. J./Berkson, B.
(1995): Going slow to go fast, in: The McKinsey Quarterly,
31, 1995, 4, S. 19-29.
Meadows, D. H./Meadows, D. L./Randers, J./Behrens III,
W. W. (1972): The Limits to Growth, New York 1972.
Milling, P. M. (1999):
System dynamics
at Mannheim University, in: Journal of the Operational
Research Society, 50, 1999.
Naill, R. F. (1992): A system dynamics model for national
energy policy planning, in: System Dynamics
Review, 8, 1992, 1, S. 1-19.
Ossimitz, G. (1995): Systemisches Denken und Modellbilden,
Arbeitspapier des Instituts für Mathematik, Statistik und
Didaktik der Mathematik der Universität Klagenfurt, Klagenfurt
1995.
Romeike, F./Spitzner, J. (2013): Von
Szenarioanalyse bis Wargaming, Betriebswirtschaftliche
Simulationen im Praxiseinsatz, Weinheim 2013.
Rosenørn, T./Kofoed, L. B. (1998): Reflection in learning
processes through simulating/gaming, in: Simulation &
Gaming, 29, 1998, 4, S. 432-440.
Sterman, J. D. (1984):
Instructions for Running the Beer Distribution Game. D-3679,
System Dynamics
Group, MIT, E60-388, Cambridge, MA 02139.
Sterman, J. D. (1989):
Modeling Managerial Behavior: Misperceptions of Feedback in
a Dynamic
Decision Making Experiment, in: Management Science, 35(3),
321-339.
Sterman, J. D. (1994):
Learning in and about complex systems; in: System Dynamics
Review, 10, 1994.
Ulrich, H./Probst, G. J. B. (1991):
Anleitung zum ganzheitlichen Denken und Handeln: Ein Brevier
für Führungskräfte, 3. Auflage, Bern/Stuttgart 1991.
Warren, K. D./Langley, P. A. (1999): The
effective communication of
system dynamics to improve insight and learning in management
education, in: Journal of the Operational Research Society,
50, 1999, 4, S. 396-404.
Whelan, J. G. (1994):
Building the Fish Banks Model and Renewable Resource
Depletion, Prepared for System Dynamics
Education Project, Sloan
School of Management, Massachusetts Institute of Technology,
July 1994.